Haciendo subconjuntos de datos
Última actualización: 2026-07-14 | Mejora esta página
Tiempo estimado: 50 minutos
Hoja de ruta
Preguntas
- ¿Cómo puedo trabajar con subconjuntos de datos en R?
Objetivos
- Ser capaz de hacer subconjuntos de vectores, factores, matrices, listas y data frames.
- Ser capaz de extraer uno o multiples elementos: por posición, por nombre, o usando operaciones de comparación.
- Ser capaz de saltar y quitar elementos de diferentes estructuras de datos.
R dispone de muchas operaciones para generar subconjuntos. Dominarlas te permitirá hacer fácilmente operaciones muy complejas en cualquier dataset.
Existen seis maneras distintas por las cuales se puede hacer un subconjunto de datos de cualquier objeto, y existen tres operadores distintos para hacer subconjuntos para las diferentes estructuras de datos.
Empecemos con el caballito de batalla de R: un vector numérico.
R
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
x
SALIDA
a b c d e
5.4 6.2 7.1 4.8 7.5 Vectores atómicos
En R, un vector puede contener palabras, números o valores lógicos. Estos son llamados vectores atómicos ya que no se pueden simplificar más.
Ya que creamos un vector ejemplo juguemos con él, ¿cómo podemos acceder a su contenido?
Accediendo a los elementos del vector usando sus índices
Para extraer elementos o datos de un vector podemos usar su índice correspondiente, empezando por uno:
R
x[1]
SALIDA
a
5.4 R
x[4]
SALIDA
d
4.8 No lo parece, pero el operador corchetes es una función. Para los vectores (y las matrices), esto significa “dame el n-ésimo elemento”.
También podemos pedir varios elementos al mismo tiempo:
R
x[c(1, 3)]
SALIDA
a c
5.4 7.1 O podemos tomar un rango del vector:
R
x[1:4]
SALIDA
a b c d
5.4 6.2 7.1 4.8 el operador : crea una sucesión de números del valor a
la izquierda hasta el de la derecha.
R
1:4
SALIDA
[1] 1 2 3 4R
c(1, 2, 3, 4)
SALIDA
[1] 1 2 3 4También podemos pedir el mismo elemento varias veces:
R
x[c(1,1,3)]
SALIDA
a a c
5.4 5.4 7.1 Si pedimos por índices mayores a la longitud del vector, R regresará un valor faltante.
R
x[6]
SALIDA
<NA>
NA Este es un vector de longitud uno que contiene un NA,
cuyo nombre también es NA.
Si pedimos el elemento en el índice 0, obtendremos un vector vacío.
R
x[0]
SALIDA
named numeric(0)La numeración de R comienza en 1
En varios lenguajes de programación (C y Python por ejemplo), el primer elemento de un vector tiene índice 0. En R, el primer elemento tiene el índice 1.
Saltando y quitando elementos
Si usamos un valor negativo como índice para un vector, R regresará cada elemento excepto lo que se ha especificado:
R
x[-2]
SALIDA
a c d e
5.4 7.1 4.8 7.5 También podemos saltar o no mostrar varios elementos:
R
x[c(-1, -5)] # o bien x[-c(1,5)]
SALIDA
b c d
6.2 7.1 4.8 Sugerencia: Orden de las operaciones
Un pequeño obstáculo para los novatos ocurre cuando tratan de saltar rangos de elementos de un vector. Es natural tratar de filtrar una sucesión de la siguiente manera:
R
x[-1:3]
Esto nos devuelve un error algo críptico:
ERROR
Error in `x[-1:3]`:
! only 0's may be mixed with negative subscriptsPero recuerda el orden de las operaciones. : es en
realidad una función. Toma como primer elemento -1 y como segundo 3, por
lo que se genera la sucesión de números:
c(-1, 0, 1, 2, 3).
La solución correcta sería empaquetar la llamada de la función dentro
de paréntesis, de está manera el operador - se aplica al
resultado:
R
x[-(1:3)]
SALIDA
d e
4.8 7.5 Para quitar los elementos de un vector, será necesario que asignes el resultado de vuelta a la variable:
R
x <- x[-4]
x
SALIDA
a b c e
5.4 6.2 7.1 7.5 Desafío 1
Dado el siguiente código:
R
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
print(x)
SALIDA
a b c d e
5.4 6.2 7.1 4.8 7.5 Encuentra al menos 3 comandos distintos que produzcan la siguiente salida:
SALIDA
b c d
6.2 7.1 4.8 Después de encontrar los tres comandos distintos, compáralos con los de tu vecino. ¿Tuvieron distintas estrategias?
R
x[2:4]
SALIDA
b c d
6.2 7.1 4.8 R
x[-c(1,5)]
SALIDA
b c d
6.2 7.1 4.8 R
x[c("b", "c", "d")]
SALIDA
b c d
6.2 7.1 4.8 R
x[c(2,3,4)]
SALIDA
b c d
6.2 7.1 4.8 Haciendo subconjuntos por nombre
Podemos extraer elementos usando sus nombres, en lugar de extraerlos por índice:
R
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # podemos nombrar un vector en la misma línea
x[c("a", "c")]
SALIDA
a c
5.4 7.1 Esta forma es mucho más segura para hacer subconjuntos: las posiciones de muchos elementos pueden cambiar a menudo cuando estamos creando una cadena de subconjuntos, ¡pero los nombres siempre permanecen iguales!
Creando subconjuntos usando operaciones lógicas
También podemos usar un vector con elementos lógicos para hacer subconjuntos:
R
x[c(FALSE, FALSE, TRUE, FALSE, TRUE)]
SALIDA
c e
7.1 7.5 Dado que los operadores de comparación (e.g. >,
<, ==) dan como resultado valores lógicos,
podemos usarlos para crear subconjuntos de manera mas sintética: la
siguiente instrucción tiene el mismo resultado que el anterior.
R
x[x > 7]
SALIDA
c e
7.1 7.5 Explicando un poco lo que sucedió, la instrucción
x>7, genera un vector lógico
c(FALSE, FALSE, TRUE, FALSE, TRUE) y después éste
selecciona los elementos de x correspondientes a los
valores TRUE.
Podemos usar == para imitar el método anterior de
indexar con nombre (recordemos que se usa == en vez de
= para comparar):
R
x[names(x) == "a"]
SALIDA
a
5.4 Sugerencia: Combinando condiciones lógicas
Muchas veces queremos combinar varios criterios lógicos. Por ejemplo, tal vez queramos encontrar todos los países en Asia o (en inglés or) Europe y (en inglés and) con esperanza de vida en cierto rango. Existen muchas operaciones para combinar vectores con elementos lógicos en R:
-
&, el operador “lógico AND”: regresaTRUEsi tanto la derecha y la izquierda sonTRUE. -
|, el operador “lógico OR”: regresaTRUE, si la derecha o la izquierda (o ambos) sonTRUE.
A veces encontrarás && y ̣|| en vez
de & y |. Los operadores de dos caracteres
solo comparan los primeros elementos de cada vector e ignoran las demás
elementos. En general no debes usar los operadores de dos caracteres en
el análisis de datos; déjalos para la programación, i.e. para decir
cuando se ejecutara una instrucción.
-
!, el operador “lógico NOT”: convierteTRUEaFALSEyFALSEaTRUE. Puede negar una sola condición lógica (e.g.!TRUEse vuelveFALSE), o un vector logical (e.g.!c(TRUE, FALSE)se vuelvec(FALSE, TRUE)).
Más aún, puedes comparar todos los elementos de un vector entre ellos
usando la función all (que regresa TRUE si
todos los elementos del vector son TRUE) y la función
any (que regresa TRUE si uno o más elementos
del vector son TRUE).
Desafío 3
Dado el siguiente código:
R
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
print(x)
SALIDA
a b c d e
5.4 6.2 7.1 4.8 7.5 Escribe un comando para crear el subconjunto de valores de
x que sean mayores a 4 pero menores que 7.
R
x_subset <- x[x<7 & x>4]
print(x_subset)
SALIDA
a b d
5.4 6.2 4.8 Sugerencia: Nombres no únicos
Debes tener en cuenta que es posible que múltiples elementos en un vector tengan el mismo nombre. (Para un data frame, las columnas pueden tener el mismo nombre —aunque R intenta evitarlo— pero los nombres de las filas deben ser únicos). Considera estos ejemplos:
R
x <- 1:3
x
SALIDA
[1] 1 2 3R
names(x) <- c('a', 'a', 'a')
x
SALIDA
a a a
1 2 3 R
x['a'] # solo devuelve el primer valor
SALIDA
a
1 R
x[names(x) == 'a'] # devuelve todos los tres valores
SALIDA
a a a
1 2 3 Sugerencia: Obteniendo ayuda para los operadores
Recuerda que puedes obtener ayuda para los operadores empaquetándolos
entre comillas: help("%in%") o ?"%in%".
Saltarse los elementos nombrados
Saltarse o eliminar elementos con nombre es un poco más difícil. Si tratamos de omitir un elemento con nombre al negar la cadena, R se queja (de una manera un poco oscura) de que no sabe cómo tomar el valor negativo de una cadena:
R
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # comenzamos nuevamente nombrando un vector en la misma línea
x[-"a"]
ERROR
Error in `-"a"`:
! invalid argument to unary operatorSin embargo, podemos usar el operador != (no igual) para
construir un vector con elementos lógicos, que es lo que nosotros
queremos:
R
x[names(x) != "a"]
SALIDA
b c d e
6.2 7.1 4.8 7.5 Saltar varios índices con nombre es un poco más difícil. Supongamos
que queremos excluir los elementos "a" y "c",
entonces intentamos lo siguiente:
R
x[names(x)!=c("a","c")]
ADVERTENCIA
Warning in names(x) != c("a", "c"): longer object length is not a multiple of
shorter object lengthSALIDA
b c d e
6.2 7.1 4.8 7.5 R hizo algo, pero también nos lanzó una advertencia que
debemos atender -¡y aparentemente nos dió la respuesta
incorrecta! (el elemento "c" se encuentra todavía en
el vector).
¿Entonces qué hizo el operador != en este caso? Esa es
una excelente pregunta.
Reciclando
Tomemos un momento para observar al operador de comparación en este código:
R
names(x) != c("a", "c")
ADVERTENCIA
Warning in names(x) != c("a", "c"): longer object length is not a multiple of
shorter object lengthSALIDA
[1] FALSE TRUE TRUE TRUE TRUE¿Por qué R devuelve TRUE como el tercer elemento de este
vector, cuando names(x)[3] != "c" es obviamente falso?.
Cuando tú usas !=, R trata de comparar cada elemento de la
izquierda con el correspondiente elemento de la derecha. ¿Qué pasa
cuando tu comparas dos elementos de diferentes longitudes?
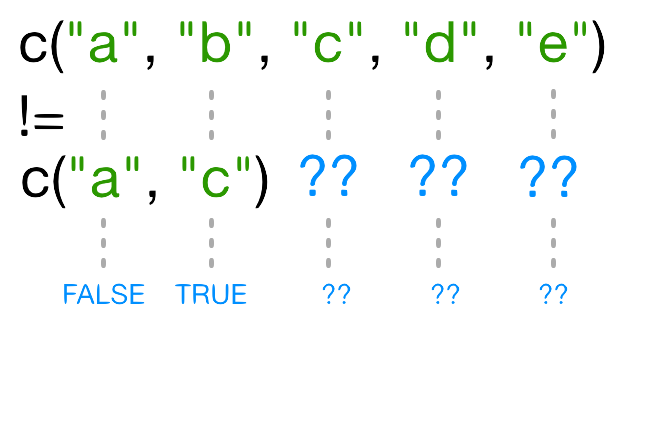
Cuando uno de los vectores es más corto que el otro, este se recicla:
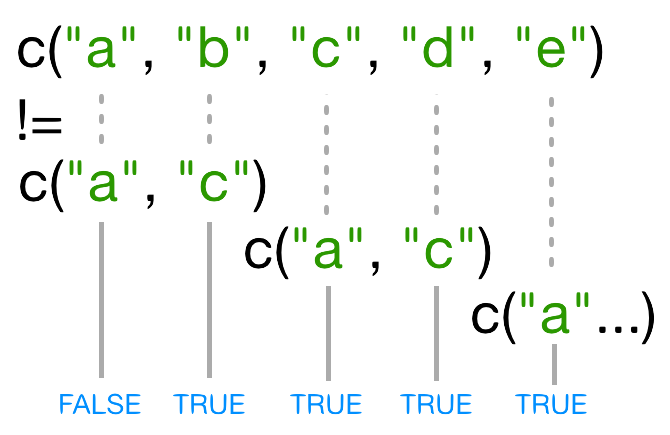
En este caso R repite c("a", "c")
tantas veces como sea necesario para emparejar names(x),
i.e. tenemos c("a","c","a","c","a"). Ya que el valor
reciclado "a"no es igual a names(x), el valor
de != es TRUE. En este caso, donde el vector
de mayor longitud (5) no es múltiplo del más pequeño (2), R lanza esta
advertencia. Si hubiéramos sido lo suficientemente desafortunados y
names(x) tuviese seis elementos, R silenciosamente
hubiera hecho las cosas incorrectas (i.e., no lo que deseábamos hacer).
Esta regla de reciclaje puede introducir bugs difíciles
de encontrar.
La manera de hacer que R haga lo que en verdad queremos (emparejar
cada uno de los elementos del argumento de la izquierda con
todos los elementos del argumento de la derecha) es usando el
operador %in%. El operador %in% toma cada uno
de los elementos del argumento de la izquierda, en este caso los nombres
de x, y pegunta, “¿este elemento ocurre en el segundo
argumento?” Aquí, como queremos excluir los valores, nosotros
también necesitamos el operador ! para cambiar la inclusión
por una no inclusión:
R
x[! names(x) %in% c("a","c") ]
SALIDA
b d e
6.2 4.8 7.5 Desafío 2
Seleccionar elementos de un vector que empareje con cualquier valor
de una lista es una tarea muy común en el análisis de datos. Por
ejemplo, el data set de gapminder contiene las
variables country y continent, pero no incluye
información de la escala. Supongamos que queremos extraer la información
de el sureste de Asia: ¿cómo podemos escribir una operación que resulte
en un vector lógico que sea TRUE para todos los países en
el sureste de Asia y FALSE en otros casos?
Supongamos que se tienen los siguientes datos:
R
seAsia <- c("Myanmar","Thailand","Cambodia","Vietnam","Laos")
## leer los datos de gapminder que bajamos en el episodio 2
gapminder <- read.csv("data/gapminder-FiveYearData.csv", header=TRUE)
## extraer la columna `country` de la **data frame** (veremos esto luego);
## convertir de factor a caracter;
## y quedarse solo con los elementos no repetidos
countries <- unique(as.character(gapminder$country))
Existe una manera incorrecta (usando solamente ==), la
cual te dará una advertencia (warning); una manera enredada de
hacerlo (usando los operadores lógicos == y |)
y una manera elegante (usando %in%). Prueba encontrar esas
maneras y explica cómo funcionan (o no).
- La manera incorrecta de hacer este problema es
countries==seAsia. Esta lanza una advertencia ("In countries == seAsia : longer object length is not a multiple of shorter object length") y la respuesta incorrecta (un vector con todos los valoresFALSE), ya que ninguno de los valores reciclados deseAsiase emparejaron correctamente para coincidir con los valores decountry. - La manera enredada (pero técnicamente correcta) de resolver este problema es
R
(countries=="Myanmar" | countries=="Thailand" |
countries=="Cambodia" | countries == "Vietnam" | countries=="Laos")
(o countries==seAsia[1] | countries==seAsia[2] | ...).
Esto da los valores correctos, pero esperamos que veas lo raro que se ve
(¿qué hubiera pasado si hubiéramos querido seleccionar países de una
lista mucho más larga?).
- La mejor manera de resolver este problema es
countries %in% seAsia, la cual es la correcta y la más sencilla de escribir (y leer).
Manejando valores especiales
En algún momento encontraremos funciones en R que no pueden manejar valores faltantes, infinito o datos indefinidos.
Existen algunas funciones especiales que puedes usar para filtrar estos datos:
-
is.naregresa todas las posiciones de un vector, matrix o data frame que contenganNA(oNaN) - de la misma manera,
is.nanyis.infinitehacen lo mismo paraNaNeInf. -
is.finiteregresa todas las posiciones de un vector, matrix o data frame que no contenganNA,NaNoInf. -
na.omitfiltra todos los valores faltantes de un vector
Haciendo subconjuntos de factores
Habiendo explorado las distintas manera de hacer subconjuntos de vectores, ¿cómo podemos hacer subconjuntos de otras estructuras de datos?
Podemos hacer subconjuntos de factores de la misma manera que con los vectores.
R
f <- factor(c("a", "a", "b", "c", "c", "d"))
f[f == "a"]
SALIDA
[1] a a
Levels: a b c dR
f[f %in% c("b", "c")]
SALIDA
[1] b c c
Levels: a b c dR
f[1:3]
SALIDA
[1] a a b
Levels: a b c dSaltar elementos no quita el nivel, incluso cuando no existan datos en esa categoría del factor:
R
f[-3]
SALIDA
[1] a a c c d
Levels: a b c dHaciendo subconjuntos de matrices
También podemos hacer subconjuntos de matrices usando la función
[ En este caso toma dos argumentos: el primero se aplica a
las filas y el segundo a las columnas:
R
set.seed(1)
m <- matrix(rnorm(6*4), ncol=4, nrow=6)
m[3:4, c(3,1)]
SALIDA
[,1] [,2]
[1,] 1.12493092 -0.8356286
[2,] -0.04493361 1.5952808Siempre puedes dejar el primer o segundo argumento vacío para obtener todas las filas o columnas respectivamente:
R
m[, c(3,4)]
SALIDA
[,1] [,2]
[1,] -0.62124058 0.82122120
[2,] -2.21469989 0.59390132
[3,] 1.12493092 0.91897737
[4,] -0.04493361 0.78213630
[5,] -0.01619026 0.07456498
[6,] 0.94383621 -1.98935170Si quisieramos acceder a solo una fila o una columna, R automáticamente convertirá el resultado a un vector:
R
m[3,]
SALIDA
[1] -0.8356286 0.5757814 1.1249309 0.9189774Si quieres mantener la salida como una matriz, necesitas especificar
un tercer argumento; drop = FALSE:
R
m[3, , drop=FALSE]
SALIDA
[,1] [,2] [,3] [,4]
[1,] -0.8356286 0.5757814 1.124931 0.9189774A diferencia de los vectores, si tratamos de acceder a una fila o columna fuera de la matriz, R arrojará un error:
R
m[, c(3,6)]
ERROR
Error in `m[, c(3, 6)]`:
! subscript out of boundsSugerencia: Arrays de más dimensiones
Cuando estamos lidiando con arrays
multi-dimensionales, cada uno de los argumentos de [
corresponden a una dimensión. Por ejemplo,en un array
3D, los primeros tres argumentos corresponden a las filas, columnas y
profundidad.
Como las matrices son vectores, podemos también hacer subconjuntos usando solo un argumento:
R
m[5]
SALIDA
[1] 0.3295078Normalmente esto no es tan útil y muchas veces difícil de leer. Sin embargo es útil notar que las matrices están acomodadas en un formato column-major por defecto. Esto significa que los elementos del vector están acomodados por columnas:
R
matrix(1:6, nrow=2, ncol=3)
SALIDA
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6Si quisieramos llenar una matriz por filas, usamos
byrow=TRUE:
R
matrix(1:6, nrow=2, ncol=3, byrow=TRUE)
SALIDA
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6Podemos también hacer subconjuntos de las matrices usando los nombres de sus filas y de sus columnas en vez de usar sus índices.
Desafío 4
Dado el siguiente código:
R
m <- matrix(1:18, nrow=3, ncol=6)
print(m)
SALIDA
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 4 7 10 13 16
[2,] 2 5 8 11 14 17
[3,] 3 6 9 12 15 18- ¿Cuál de los siguientes comandos extraerá los valores 11 y 14?
A. m[2,4,2,5]
B. m[2:5]
C. m[4:5,2]
D. m[2,c(4,5)]
D
Haciendo subconjuntos de listas
Ahora introduciremos un nuevo operador para hacer subconjuntos.
Existen tres funciones para hacer subconjuntos de listas. Ya las hemos
visto cuando aprendimos los vectores atómicos y las matrices:
[, [[ y $.
Usando [ siempre se obtiene una lista. Si quieres un
subconjunto de una lista, pero no quieres extraer un
elemento, entonces probablemente usarás [.
R
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(mtcars))
xlist[1]
SALIDA
$a
[1] "Software Carpentry"Esto regresa una lista de un elemento.
Podemos hacer subconjuntos de elementos de la lista de la misma
manera que con los vectores atómicos usando [. Las
operaciones de comparación sin embargo no funcionan, ya que no son
recursivas, estas probarán la condición en la estructura de datos de los
elementos de la lista, y no en los elementos individuales de dichas
estructuras de datos.
R
xlist[1:2]
SALIDA
$a
[1] "Software Carpentry"
$b
[1] 1 2 3 4 5 6 7 8 9 10Para extraer elementos individuales de la lista, tendrás que hacer
uso de la función doble corchete: [[.
R
xlist[[1]]
SALIDA
[1] "Software Carpentry"Nota que ahora el resultados es un vector, no una lista.
No puedes extraer más de un elemento al mismo tiempo:
R
xlist[[1:2]]
ERROR
Error in `xlist[[1:2]]`:
! subscript out of boundsTampoco puedes usarlo para saltar elementos:
R
xlist[[-1]]
ERROR
Error in `xlist[[-1]]`:
! invalid negative subscript in get1index <real>Pero tú puedes usar los nombres para hacer subconjuntos y extraer elementos:
R
xlist[["a"]]
SALIDA
[1] "Software Carpentry"La función $ es una manera abreviada para extraer
elementos por nombre:
R
xlist$data
SALIDA
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1Desafío 5
Dada la siguiente lista:
R
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(mtcars))
Usando tu conocimiento para hacer subconjuntos de listas y vectores,
extrae el número 2 de xlist. Pista: el número 2 está
contenido en el elemento “b” de la lista.
R
xlist$b[2]
SALIDA
[1] 2R
xlist[[2]][2]
SALIDA
[1] 2R
xlist[["b"]][2]
SALIDA
[1] 2Desafío 6
Dado un modelo lineal:
R
mod <- aov(pop ~ lifeExp, data=gapminder)
Extrae los grados de libertad residuales (pista:
attributes() te puede ayudar)
R
attributes(mod) ## `df.residual` es uno de los nombres de `mod`
R
mod$df.residual
Data frames
Recordemos que las data frames son listas, por lo que aplican reglas similares. Sin embargo estos también son objetos de dos dimensiones:
[ con un argumento funcionará de la misma manera que
para las listas, donde cada elemento de la lista corresponde a una
columna. El objeto devuelto será una data frame:
R
head(gapminder[3])
SALIDA
pop
1 8425333
2 9240934
3 10267083
4 11537966
5 13079460
6 14880372Similarmente, [[ extraerá una sola columna:
R
head(gapminder[["lifeExp"]])
SALIDA
[1] 28.801 30.332 31.997 34.020 36.088 38.438Con dos argumentos, [ se comporta de la misma manera que
para las matrices:
R
gapminder[1:3,]
SALIDA
country year pop continent lifeExp gdpPercap
1 Afghanistan 1952 8425333 Asia 28.801 779.4453
2 Afghanistan 1957 9240934 Asia 30.332 820.8530
3 Afghanistan 1962 10267083 Asia 31.997 853.1007Si nuestro subconjunto es una sola fila, el resultado será una data frame (porque los elementos son de distintos tipos):
R
gapminder[3,]
SALIDA
country year pop continent lifeExp gdpPercap
3 Afghanistan 1962 10267083 Asia 31.997 853.1007Pero para una sola columna el resultado será un vector (esto puede
cambiarse con el tercer argumento, drop = FALSE).
Desafío 7
Corrige cada uno de los siguientes errores para hacer subconjuntos de data frames:
- Extraer observaciones colectadas en el año 1957
- Extraer todas las columnas excepto de la 1 a la 4
R
gapminder[,-1:4]
- Extraer las filas donde la esperanza de vida es mayor a 80 años
R
gapminder[gapminder$lifeExp > 80]
- Extraer la primer fila, y la cuarta y quinta columna
(
lifeExpygdpPercap).
R
gapminder[1, 4, 5]
- Avanzado: extraer las filas que contienen información para los años 2002 y 2007
R
gapminder[gapminder$year == 2002 | 2007,]
Corrige cada uno de los siguientes errores para hacer subconjuntos de data frames:
- Extraer observaciones colectadas en el año 1957
R
# gapminder[gapminder$year = 1957,]
gapminder[gapminder$year == 1957,]
- Extraer todas las columnas excepto de la 1 a la 4
R
# gapminder[,-1:4]
gapminder[,-c(1:4)]
- Extraer las filas donde la esperanza de vida es mayor a 80 años
R
# gapminder[gapminder$lifeExp > 80]
gapminder[gapminder$lifeExp > 80,]
- Extraer la primer fila, y la cuarta y quinta columna
(
lifeExpygdpPercap).
R
# gapminder[1, 4, 5]
gapminder[1, c(4, 5)]
- Avanzado: extraer las filas que contienen información para los años 2002 y 2007
R
# gapminder[gapminder$year == 2002 | 2007,]
gapminder[gapminder$year == 2002 | gapminder$year == 2007,]
gapminder[gapminder$year %in% c(2002, 2007),]
Desafío 8
¿Por qué
gapminder[1:20]regresa un error? ¿En qué difiere degapminder[1:20, ]?Crea un
data.framellamadogapminder_smallque solo contenga las filas del 1 al 9 y del 19 al 23. Puedes hacerlo en uno o dos pasos.
gapminderes undata.framepor lo que para hacer un subconjunto necesita dos dimensiones.gapminder[1:20, ]genera un subconjunto de los datos de las primeras 20 filas y todas las columnas.
R
gapminder_small <- gapminder[c(1:9, 19:23),]
- Los índices en R comienzan con 1, no con 0.
- Acceso a un elemento por posición usando
[]. - Acceso a un rango de datos usando
[min:max]. - Acceso a subconjuntos arbitrarios usando
[c(...)]. - Usar operaciones lógicas y vectores lógicos para acceder a subconjuntos de datos