División y combinación de data frames con plyr
Última actualización: 2026-07-28 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo hacer diferentes cálculos sobre diferentes conjuntos de datos?
Objetivos
- Estar apto a usar la estrategia divide-aplica-combina para el análisis de datos.
Previamente vimos como puedes usar funciones para simplificar tu
código. Definimos la función calcGDP, la cual toma el
dataset gapminder, y multiplica la columna de población
por la columna GDP per cápita. También definimos argumentos adicionales
de modo que pudiéramos filtrar por "year" o por
"country":
R
# Toma un dataset y multiplica la columna population con
# la columna GDP per cápita.
calcGDP <- function(dat, year=NULL, country=NULL) {
if(!is.null(year)) {
dat <- dat[dat$year %in% year, ]
}
if (!is.null(country)) {
dat <- dat[dat$country %in% country,]
}
gdp <- dat$pop * dat$gdpPercap
new <- cbind(dat, gdp=gdp)
return(new)
}
Una tarea común que encontrarás mientras trabajes con datos, es que querrás hacer cálculos en diferentes grupos sobre los datos. En el ejemplo de arriba, simplemente calculamos el GDP por multiplicar dos columnas juntas. ¿Pero qué tal si queremos calcular la media GDP por continente?
Podríamos ejecutar calcGDP y entonces tomar la media de
cada continente:
R
withGDP <- calcGDP(gapminder)
mean(withGDP[withGDP$continent == "Africa", "gdp"])
SALIDA
[1] 20904782844R
mean(withGDP[withGDP$continent == "Americas", "gdp"])
SALIDA
[1] 379262350210R
mean(withGDP[withGDP$continent == "Asia", "gdp"])
SALIDA
[1] 227233738153Pero esto no es muy bonito. Sí, por usar una función, has reducido substancialmente la cantidad de repeticiones. Esto es bonito. Pero aún hay repeticiones. La repetición te costará tiempo, tanto ahora como más tarde, y potencialmente introducirás algunos errores desagradables.
Podriamos escribir una nueva función que sea flexible como
calcGDP, pero esta también requiere una gran cantidad de
esfuerzo y pruebas para hacerlo bien.
El problema abstracto que estamos encontrando aquí es conocido como “divide-aplica-combina (split-apply-combine)”:
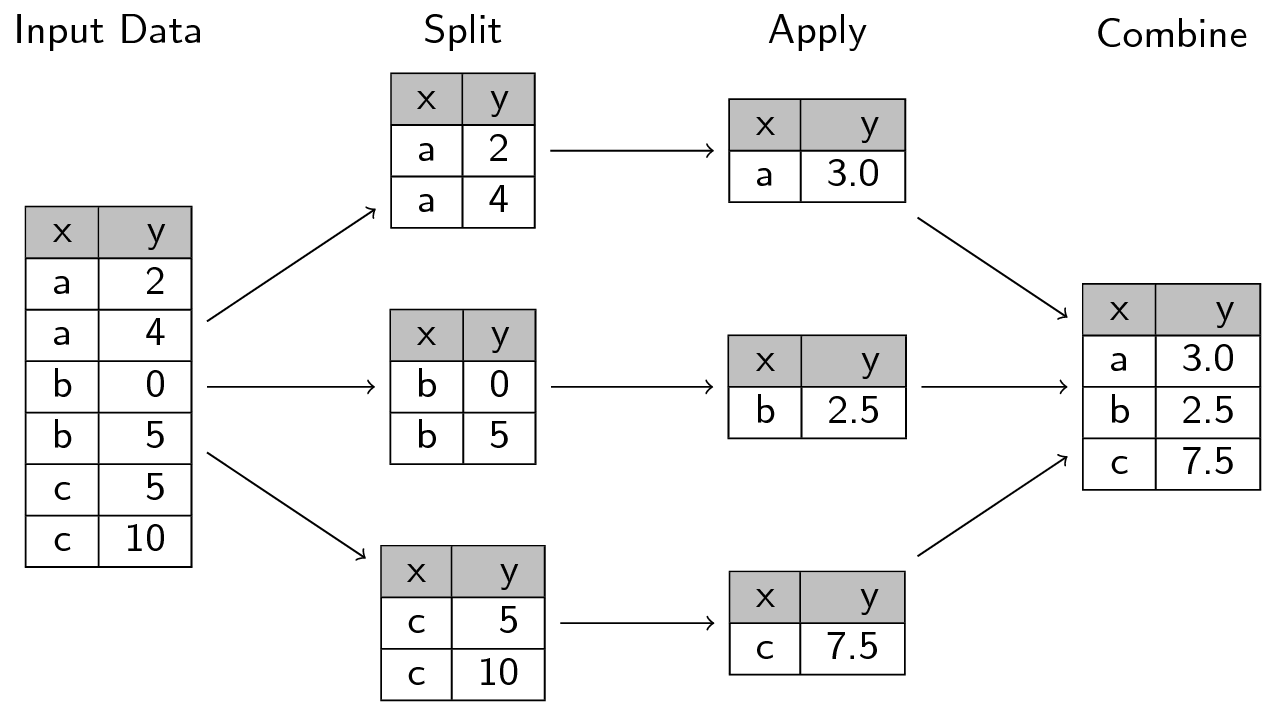
Nosotros queremos dividir (split) nuestros datos dentro de grupos, en este caso continentes, aplicar (apply) algunos cálculos sobre este grupo y, opcionalmente, combinar (combine) los resultados más tarde.
El paquete plyr
Para aquellos que han usado antes R, es posible que estén
familiarizados con la familia de funciones apply. Mientras
que las funciones integradas de R funcionan, vamos a introducirte a otro
método para resolver el problema “split-apply-combine”. El paquete plyr proporciona un conjunto de
funciones que encontramos más amigables de usar para resolver este
problema.
Instalamos este paquete en un desafío anterior. Vamos a cargarlo ahora:
R
library("plyr")
Plyr tiene una función para operar sobre listas o
**lists** , **data.frames** y
**arrays** (matrices, o vectores n-dimensional). Cada
función realiza:
- Una operación de división (splitting).
- Aplica (apply) una función sobre cada una de las partes a la vez.
- Recombina (recombine) los datos de salida como un simple objeto de datos.
Las funciones se nombran en función de la estructura de datos que esperan como entrada, y la estructura de datos que desea devolver como salida: [a]rray, [l]ist, o [d]ata.frame. La primera letra corresponde a la estructura de datos de entrada, la segunda letra a la estructura de datos de salida, y luego el resto de la función se llama “ply”.
Esto nos da 9 funciones básicas **ply. Hay adicionalmente un árbol de
funciones las cuales solo realizarán la división y aplicación de los
pasos y ningún paso combinado. Ellas son nombradas por sus datos de
entrada y representan una salida nula con un _ (Ver
tabla)
Note que el uso de “array” de plyr es diferente a R, un array en ply puede incluir a vector o matriz.
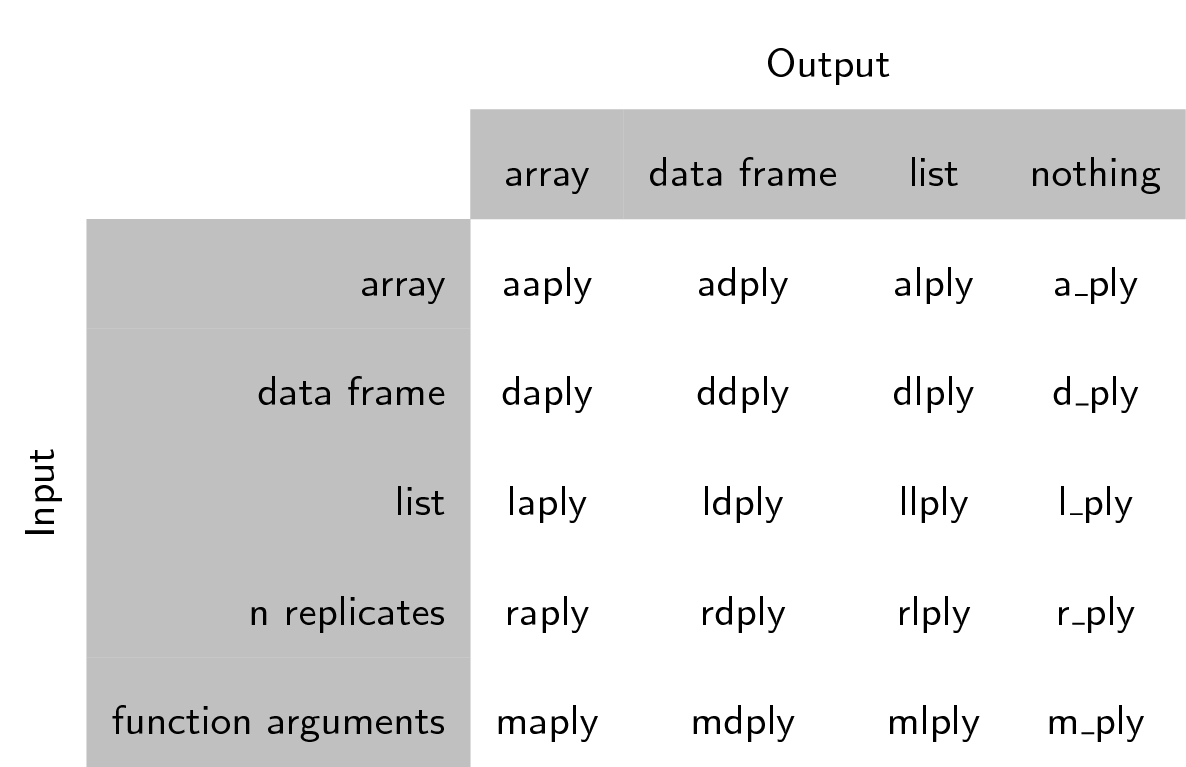
Cada una de las funciones de xxply
(daply,ddply,
llply,laply, …) tiene la misma estructura y 4
características clave:
R
xxply(.data, .variables, .fun)
- La primera letra del nombre de la función da el tipo de la entrada y el segundo da el tipo de la salida.
-
.data– Es el objeto de datos a ser procesado -
.variables– identifica la variable para hacer la división -
.fun– Da la función a ser llamada para cada pieza
Ahora podemos calcular rápidamente la media GDP por
"continent":
R
ddply(
.data = calcGDP(gapminder),
.variables = "continent",
.fun = function(x) mean(x$gdp)
)
SALIDA
continent V1
1 Africa 20904782844
2 Americas 379262350210
3 Asia 227233738153
4 Europe 269442085301
5 Oceania 188187105354Veamos el código anterior:
- La función
ddplyrecibe de entrada undata.frame(La función empieza con una d) y regresa otrodata.frame(la 2da letra es una d) - El primer argumento que dimos fue el
data.frameen el que queríamos operar: en este caso, los datos delgapminder. Primero llamamos a la funcióncalcGDPpara agregar la columnagdpa nuestra variable data. - El segundo argumento indica nuestro criterio para dividir: En este
caso la columna
"continent". Ten en cuenta que le dimos el nombre de la columna, no los valores de la columna como habíamos hecho previamente con los subconjuntos.Plyrse encarga de los detalles de la implementación por ti. - El tercer argumento es la función que queremos aplicar a cada grupo
de datos. Tenemos que definir nuestra propia función corta aquí: cada
subconjunto de datos va almacenado en
x, el primer argumento de la función. Esta es una función anónima: no la hemos definido en otra parte y no tiene nombre. Solo existe en el ámbito de nuestro llamado addply.
¿Qué pasa si queremos un tipo diferente de estructura de datos de salida?:
R
dlply(
.data = calcGDP(gapminder),
.variables = "continent",
.fun = function(x) mean(x$gdp)
)
SALIDA
$Africa
[1] 20904782844
$Americas
[1] 379262350210
$Asia
[1] 227233738153
$Europe
[1] 269442085301
$Oceania
[1] 188187105354
attr(,"split_type")
[1] "data.frame"
attr(,"split_labels")
continent
1 Africa
2 Americas
3 Asia
4 Europe
5 OceaniaLlamamos a la misma función otra vez, pero cambiamos la segunda letra
por una l, asi que la salida fue regresada como una
lista.
Podemos especificar múltiples columnas para agrupar:
R
ddply(
.data = calcGDP(gapminder),
.variables = c("continent", "year"),
.fun = function(x) mean(x$gdp)
)
SALIDA
continent year V1
1 Africa 1952 5992294608
2 Africa 1957 7359188796
3 Africa 1962 8784876958
4 Africa 1967 11443994101
5 Africa 1972 15072241974
6 Africa 1977 18694898732
7 Africa 1982 22040401045
8 Africa 1987 24107264108
9 Africa 1992 26256977719
10 Africa 1997 30023173824
11 Africa 2002 35303511424
12 Africa 2007 45778570846
13 Americas 1952 117738997171
14 Americas 1957 140817061264
15 Americas 1962 169153069442
16 Americas 1967 217867530844
17 Americas 1972 268159178814
18 Americas 1977 324085389022
19 Americas 1982 363314008350
20 Americas 1987 439447790357
21 Americas 1992 489899820623
22 Americas 1997 582693307146
23 Americas 2002 661248623419
24 Americas 2007 776723426068
25 Asia 1952 34095762661
26 Asia 1957 47267432088
27 Asia 1962 60136869012
28 Asia 1967 84648519224
29 Asia 1972 124385747313
30 Asia 1977 159802590186
31 Asia 1982 194429049919
32 Asia 1987 241784763369
33 Asia 1992 307100497486
34 Asia 1997 387597655323
35 Asia 2002 458042336179
36 Asia 2007 627513635079
37 Europe 1952 84971341466
38 Europe 1957 109989505140
39 Europe 1962 138984693095
40 Europe 1967 173366641137
41 Europe 1972 218691462733
42 Europe 1977 255367522034
43 Europe 1982 279484077072
44 Europe 1987 316507473546
45 Europe 1992 342703247405
46 Europe 1997 383606933833
47 Europe 2002 436448815097
48 Europe 2007 493183311052
49 Oceania 1952 54157223944
50 Oceania 1957 66826828013
51 Oceania 1962 82336453245
52 Oceania 1967 105958863585
53 Oceania 1972 134112109227
54 Oceania 1977 154707711162
55 Oceania 1982 176177151380
56 Oceania 1987 209451563998
57 Oceania 1992 236319179826
58 Oceania 1997 289304255183
59 Oceania 2002 345236880176
60 Oceania 2007 403657044512R
daply(
.data = calcGDP(gapminder),
.variables = c("continent", "year"),
.fun = function(x) mean(x$gdp)
)
SALIDA
year
continent 1952 1957 1962 1967 1972
Africa 5992294608 7359188796 8784876958 11443994101 15072241974
Americas 117738997171 140817061264 169153069442 217867530844 268159178814
Asia 34095762661 47267432088 60136869012 84648519224 124385747313
Europe 84971341466 109989505140 138984693095 173366641137 218691462733
Oceania 54157223944 66826828013 82336453245 105958863585 134112109227
year
continent 1977 1982 1987 1992 1997
Africa 18694898732 22040401045 24107264108 26256977719 30023173824
Americas 324085389022 363314008350 439447790357 489899820623 582693307146
Asia 159802590186 194429049919 241784763369 307100497486 387597655323
Europe 255367522034 279484077072 316507473546 342703247405 383606933833
Oceania 154707711162 176177151380 209451563998 236319179826 289304255183
year
continent 2002 2007
Africa 35303511424 45778570846
Americas 661248623419 776723426068
Asia 458042336179 627513635079
Europe 436448815097 493183311052
Oceania 345236880176 403657044512Puedes usar estas funciones en lugar de ciclos for (y
generalmente es mas rápido). Para remplazar un ciclo ‘for’, pon el
código que estaba en el cuerpo del ciclo for dentro de la
función anónima.
R
d_ply(
.data=gapminder,
.variables = "continent",
.fun = function(x) {
meanGDPperCap <- mean(x$gdpPercap)
print(paste(
"La media GDP per cápita para", unique(x$continent),
"es", format(meanGDPperCap, big.mark=",")
))
}
)
SALIDA
[1] "La media GDP per cápita para Africa es 2,193.755"
[1] "La media GDP per cápita para Americas es 7,136.11"
[1] "La media GDP per cápita para Asia es 7,902.15"
[1] "La media GDP per cápita para Europe es 14,469.48"
[1] "La media GDP per cápita para Oceania es 18,621.61"Sugerencia: Imprimiendo números
La función format puede ser usada para imprimir los
valores numéricos
“bonitos” en los mensajes.
Desafío 1
Calcula el promedio de vida esperado por "continent".
¿Quién tiene el promedio mas alto? ¿Quién tiene el mas pequeño?
Desafío 2
Calcula el promedio de vida esperado por "continent" y
"year". ¿Quién tiene el promedio mas grande y mas corto en
2007? ¿Quién tiene el cambio mas grande entre 1952 y 2007?
Desafío Avanzado
Calcula la diferencia en la media de vida esperada entre los años
1952 y 2007 a partir de la salida del desafío 2 usando una de las
funciones plyr.
Desafío alterno si la clase parece perdida
Sin ejecutarlos, cuál de los siguientes calculará el promedio de la esperanza de vida por continente:
R
ddply(
.data = gapminder,
.variables = gapminder$continent,
.fun = function(dataGroup) {
mean(dataGroup$lifeExp)
}
)
R
ddply(
.data = gapminder,
.variables = "continent",
.fun = mean(dataGroup$lifeExp)
)
R
ddply(
.data = gapminder,
.variables = "continent",
.fun = function(dataGroup) {
mean(dataGroup$lifeExp)
}
)
R
adply(
.data = gapminder,
.variables = "continent",
.fun = function(dataGroup) {
mean(dataGroup$lifeExp)
}
)
- Uso del paquete
plyrpara dividir datos, aplicar funciones sobre subconjuntos, y combinar los resultados