Todo en una sola página
Content from Control Automatizado de Versiones
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 5 minutos
Hoja de ruta
Preguntas
- ¿Qué es el control de versiones y por qué se deberá usar?
Objetivos
- Comprender los beneficios de usar un sistema automático de control de versiones.
- Comprender los fundamentos básicos del funcionamiento de Git.
Empezaremos por explorar cómo el control de versiones puede ser usado para hacer un seguimiento de lo que hizo una persona y cuándo. Incluso si no se está colaborando con otras personas, el control automatizado de versiones es mucho mejor que la siguiente situación:

“Piled Higher and Deeper” por Jorge Cham, http://www.phdcomics.com
Todos hemos estado en esta situación alguna vez: parece ridículo tener varias versiones casi idénticas del mismo documento. Algunos procesadores de texto nos permiten lidiar con esto un poco mejor, como por ejemplo el Track Changes de Microsoft Word, el historial de versiones de Google o la grabación y visualización de cambios de LibreOffice.
Los sistemas de control de versiones comienzan con una versión básica del documento y luego van guardando sólo los cambios que se hicieron en cada paso del proceso. Se puede pensar en ello como en una cinta: si se rebobina la cinta y se inicia de nuevo en el documento base, se puede reproducir cada cambio y terminar con la versión más reciente.

Una vez que piensas en los cambios como separados del documento en sí, entonces se puede pensar en “deshacer” diferentes conjuntos de cambios en el documento base y obtener así diferentes versiones del documento. Por ejemplo, dos usuarios pueden hacer conjuntos independientes de cambios basados en el mismo documento.

A menos que haya conflictos, se puede incluso tener dos conjuntos de cambios en el mismo documento base.

Un sistema de control de versiones es una herramienta que realiza un seguimiento de estos cambios para nosotros y nos ayuda a controlar la versión y fusionar nuestros archivos. Nos permite decidir qué cambios conforman la siguiente versión, a lo que llamamos hacer un commit, y mantiene metadatos útiles sobre dichos cambios. El historial completo de commits para un proyecto en particular y sus metadatos forman un repositorio. Los repositorios pueden mantenerse sincronizados en diferentes computadoras, facilitando así la colaboración entre diferentes personas.
La larga historia de los sistemas de control de versiones
Los sistemas automatizados de control de versiones no son nada nuevo. Herramientas como RCS, CVS o Subversion han existido desde principios de los 1980 y son utilizadas por muchas grandes empresas. Sin embargo, muchos de estos han sido relegados debido a lo limitado de su capacidad. En particular, los sistemas más modernos, como Git y Mercurial son distribuidos, lo que significa que no necesitan un servidor centralizado para alojar el repositorio. Estos sistemas modernos también incluyen potentes herramientas de fusión que hacen posible que múltiples autores trabajen dentro de los mismos archivos simultáneamente.
¿Qué harías en las siguientes situaciones?
Imagina que has redactado un excelente párrafo para un artículo que estás escribiendo, pero más tarde lo estropeas. ¿Cómo recuperarías aquella excelente versión de la conclusión? ¿Es esto posible?
Imagina que tienes 5 coautores. ¿Cómo administrarías los cambios y
comentarios que ellos hagan en el artículo? Si usas LibreOffice Writer o
Microsoft Word, ¿qué sucede si aceptas los cambios realizados con la
opción Track Changes? ¿Tienes un historial de esos
cambios?
- El control de versiones es como un ‘deshacer’ sin límites.
- El control de versiones permite que mucha gente trabaje en lo mismo en paralelo.
Content from Configurando Git
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 5 minutos
Hoja de ruta
Preguntas
- ¿Cómo me preparo para utilizar Git?
Objetivos
- Configurar
gitla primera vez que utilice la computadora. - Comprender el significado del flag de configuración
--global.
Cuando usamos Git en una computadora por primera vez, es necesario configurar algunas cosas. A continuación se presentan algunos ejemplos de configuraciones que estableceremos a medida que trabajemos con Git:
- nombre y correo electrónico,
- cuál es nuestro editor de texto preferido,
- y que queremos utilizar estos ajustes globalmente (es decir, para cada proyecto).
En la línea de comandos, los comandos de Git se escriben como
git verb, dondeverb es lo que queremos hacer.
Así es como Drácula configura su nueva computadora:
BASH
$ git config --global user.name "Vlad Dracula"
$ git config --global user.email "vlad@tran.sylvan.ia"Utiliza tu propio nombre y dirección de correo electrónico en lugar de los de Drácula. El nombre de usuario y el correo electrónico se asociarán con tu actividad posterior de Git, lo que significa que cualquier cambio realizado en GitHub, BitBucket, GitLab u otro servidor de Git en una lección posterior incluirá esta información.
Finales de línea
Al igual que con otras teclas, cuando haces click en la tecla ‘Enter’ de tu teclado, tu computadora codifica este input como un caracter. Por razones que son demasiado largas para explicar aquí, diferentes sistemas operativos usan diferentes caracteres para representar el final de una línea. (También son conocidas como newlines o line breaks.) Como Git usa éstos caracteres para comparar archivos, esto puede causar problemas inesperados cuando se edita un archivo en máquinas diferentes.
Puedes cambiar el modo en que Git reconoce y codifica finales de
línea usando el comando core.autocrlf con
git config. Se recomiendan las siguientes
configuraciones:
En OS X y Linux:
Y en Windows:
Puedes leer más sobre este tema en esta página de GitHub.
Para estas lecciones, estaremos interactuando con GitHub, por lo tanto la dirección de
correo electrónico utilizada debe ser la misma que utilizaste al
configurar tu cuenta de GitHub. Si te preocupa la privacidad, revisa las
instrucciones de GitHub para mantener tu dirección de correo electrónico
privada. Si eliges utilizar una dirección de correo electrónico
privada con GitHub, usa la misma dirección de correo electrónico para el
valor user.email, por ejemplo,
username@users.noreply.github.com
reemplazandousername con tu nombre de usuario de GitHub.
Puedes cambiar la dirección de correo electrónico posteriormente
utilizando el comando git config nuevamente.
Drácula también tiene que establecer su editor de texto favorito, siguiendo esta tabla:
| Editor | Comando de configuración |
|---|---|
| Atom | $ git config --global core.editor "atom --wait" |
| nano | $ git config --global core.editor "nano -w" |
| TextWrangler (Mac) | $ git config --global core.editor "edit -w" |
| Sublime Text (Mac) | $ git config --global core.editor "subl -n -w" |
| Sublime Text (Win, 32-bit) | $ git config --global core.editor "'c:/program files (x86)/sublime text 3/sublime_text.exe' -w" |
| Sublime Text (Win, 64-bit) | $ git config --global core.editor "'c:/program files/sublime text 3/sublime_text.exe' -w" |
| Notepad++ (Win, 32-bitl) | $ git config --global core.editor "'c:/program files (x86)/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin" |
| Notepad++ (Win, 64-bit) | $ git config --global core.editor "'c:/program files/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin" |
| Kate (Linux) | $ git config --global core.editor "kate" |
| Gedit (Linux) | $ git config --global core.editor "gedit --wait --new-window" |
| Scratch (Linux) | $ git config --global core.editor "scratch-text-editor" |
| emacs | $ git config --global core.editor "emacs" |
| vim | $ git config --global core.editor "vim" |
| Visual Studio Code | $ git config --global core.editor "code --wait" |
Es posible reconfigurar el editor de texto para Git siempre que quieras.
Saliendo de Vim
Ten en cuenta que vim es el editor por defecto para
muchos programas, si no has utilizadovim antes y deseas
salir de una sesión, presiona la tecla Esc y posteriormente
escribe : q! y Enter.
Los cuatro comandos que acabamos de ejecutar sólo se tienen que
ejecutar una vez: la flag --global le dice a Git que use la
configuración para cada proyecto, en tu cuenta de usuario, en esta
computadora.
Puedes comprobar tu configuración en cualquier momento:
Puedes cambiar la configuración tantas veces como quieras: sólo usa los mismos comandos para elegir otro editor o actualizar tu correo electrónico.
Proxy
En algunas redes es necesario usar un proxy. Si este es el caso, es posible que también necesites proporcionarle a Git el proxy:
Para deshabilitar el proxy, utiliza
- Use
git configpara configurar un nombre de usuario, email, editor, y otras preferencias.
Content from Creando un repositorio
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 10 minutos
Hoja de ruta
Preguntas
- ¿Dónde almacena Git la información?
Objetivos
- Crear un repositorio local de Git.
Una vez que Git está configurado, podemos comenzar a usarlo. Vamos a crear un directorio para nuestro trabajo y nos movemos dentro de ese directorio:
Después le indicamos a Git hacer de planets un repository— un lugar donde Git
puede almacenar las versiones de nuestros archivos:
Si usamos ls para mostrar el contenido del directorio,
parece que nada ha cambiado:
Pero si agregamos la flag -a para mostrar todo, podemos
ver que Git ha creado un directorio oculto dentro de
planets llamado .git:
SALIDA
. .. .gitGit utiliza este subdirectorio especial para almacenar toda la
información del proyecto, incluyendo todos los archivos y
subdirectorios. Si alguna vez borramos el directorio .git,
perderemos la historia del proyecto.
Podemos revisar que todo esté configurado correctamente pidiendo a Git que nos informe el estado de nuestro proyecto:
Si estás utilizando una versión de git distinta a la que yo utilizo, el output puede ser ligeramente distinto.
SALIDA
# On branch master
#
# Initial commit
#
nothing to commit (create/copy files and use "git add" to track)Lugares para crear un repositorio Git
Ademas de rastrear la información sobre los planetas (el proyecto que
ya creamos), Drácula también quiere rastrear la información sobre las
lunas. A pesar de las preocupaciones de Wolfman, Drácula crea el
sub-directorio moons dentro de su directorio
planets ingresando la siguiente secuencia de comandos:
BASH
$ cd # volver al directorio de inicio
$ mkdir planets # crear un nuevo diretorio llamado planets
$ cd planets # entrar al directorio planets
$ git init # hacer del directorio planets directory un repositorio Git
$ mkdir moons # crear un subdirectorio planets/moons
$ cd moons # entrar al directorio planets/moons
$ git init # hacer del subdirectorio moons un repositorio Git¿Es necesario correr el comando git init en el
sub-directorio moons para poder realizar el seguimiento de
los archivos almacenados en este directorio?
No. Dracula no necesita transformar el sub-directorio
moons en un repositorio Git, porque el repositorio
planets realizará el seguimiento de todos los archivos,
sub-directorios y archivos de los sub-directorios dentro del directorio
planets. Entonces, a fin de poder hacer un seguimiento de
toda la información sobre moons, Dracula sólo necesita
agregar el sub-directorio moons al directorio
planets.
Además, los repositorios Git pueden interferir entre sí si están
“anidados” dentro de otro directorio: el repositorio exterior intentará
controlar la versión del repositorio interno. Por lo tanto, lo mejor es
crear cada nuevo repositorio Git en un directorio separado. Para
asegurarte que no hay un repositorio en conflicto en el directorio,
revisa el output de git status. Si se parece a lo
siguiente, podrás crear un nuevo repositorio como se ha mostrado
arriba:
SALIDA
fatal: Not a git repository (or any of the parent directories): .gitCorrigiendo errores de
git init
Wolfman le explica a Dracula cómo un repositorio anidado es redudante
y puede causar problemas ms adelante. Dracula quiere eliminar el
repositorio anidado. Cómo puede Dracula deshacer el último
git init en el sub-directorio moons?
Para deshacerse de este pequeño error, Dracula puede simplemente
eliminar el directorio .git del subdirectorio
moons. Para ello puede ejecutar el siguiente comando desde
el interior del directorio moons:
¡Pero ten cuidado! Ejecutar este comando en el directorio incorrecto
eliminará toda la historia git de un proyecto que podrías querer
conservar. Por lo tanto, revisa siempre tu directorio actual usando el
comando pwd.
-
git initinicializa un repositorio.
Content from Rastreando Cambios
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 20 minutos
Hoja de ruta
Preguntas
- ¿Cómo registro cambios en Git?
- ¿Cómo reviso el estatus de mi repositorio de control de versiones?
- ¿Cómo registro notas acerca de los cambios que he hecho y por qué?
Objetivos
- Ir a través del ciclo modificar-agregar-commit para uno o más archivos.
- Explicar dónde se almacena la información en cada etapa del flujo de trabajo de un commit de Git.
- Distinguir entre mensajes descriptivos y no-descriptivos de un commit.
Primero asegúrate que estamos aún en el directorio correcto. Deberías
estar en el directorio planets.
Si aún estás en moons navega de regreso a
planets
Vamos a crear un archivo llamado mars.txt que contiene
algunas notas sobre la aptitud del Planeta Rojo como base. Usaremos
nano para editar el archivo; puedes usar el editor que
prefieras. En particular, éste no tiene que ser el
core.editor que definiste globalmente con anterioridad.
Pero recuerda, los comandos bash para crear o editar un
nuevo archivo van a depender del editor que tú escojas (podría no ser
nano). Para un repaso sobre editores de texto, echa un
vistazo a “¿Qué
editor usar?” en la lección La terminal de
Unix .
Ingresa el texto siguiente en el archivo mars.txt:
SALIDA
Cold and dry, but everything is my favorite colormars.txt ahora contiene una sola línea, la cual podemos
ver ejecutando:
SALIDA
mars.txtSALIDA
Cold and dry, but everything is my favorite colorSi revisamos el estatus de nuestro proyecto otra vez, Git nos dice que ha reconocido el nuevo archivo:
SALIDA
On branch master
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
mars.txt
nothing added to commit but untracked files present (use "git add" to track)El mensaje de “untracked files” significa que un archivo no está
siendo rastreado por Git. Podemos poner los archivos en el
staging area con git add.
y luego verifica que hizo lo correcto:
SALIDA
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: mars.txt
Git ahora sabe que tiene que seguir la pista de
mars.txt, pero no ha registrado los cambios con un
commit aún. Para que lo haga, necesitamos ejecutar un
comando más:
SALIDA
[master (root-commit) f22b25e] Start notes on Mars as a base
1 file changed, 1 insertion(+)
create mode 100644 mars.txtCuando ejecutamos git commit, Git toma todo lo que le
hemos dicho que salve usando git add y almacena una copia
permanentemente dentro del directorio especial .git. Esta
copia permanente es llamada un commit (o revision) y su identificador corto es
f22b25e (Tu commit podría tener otro
identificador.)
Usamos la flag -m (por “message”) para
registrar un comentario corto, descriptivo y específico que nos ayudará
a recordar más tarde lo que hicimos y por qué. Si ejecutamos
git commit sin la opción -m, Git ejecutará
nano (o cualquier otro editor que hayamos configurado como
core.editor) para que podamos escribir un mensaje más
largo.
Los Buenos mensajes en un commit inician con un breve resumen (<50 caracteres) de los cambios hechos en el commit. Si quieres entrar en más detalles, agrega una línea blanca entre la línea del resumen y tus notas adicionales.
Si ejecutamos git status ahora:
SALIDA
On branch master
nothing to commit, working directory cleannos dice que todo está actualizado. Si queremos saber lo que hemos
hecho recientemente, podemos pedir a Git que nos muestre la historia del
proyecto usando git log:
SALIDA
commit f22b25e3233b4645dabd0d81e651fe074bd8e73b
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 09:51:46 2013 -0400
Start notes on Mars as a basegit log lista todos los commits hechos
a un repositorio en orden cronológico inverso. El listado de cada
commit incluye el identificador completo del
commit (el cual comienza con el mismo caracter que el
identificador corto que imprime el comando git commit
anterior), el autor del commit, cuándo fue creado, y el
mensaje de registro que se le dio a Git cuando el
commit fue creado.
¿Dónde están mis cambios?
Si ejecutamos ls en este punto, aún veremos un solo
archivo llamado mars.txt. Esto es porque Git guarda
información acerca de la historia de los archivos en el directorio
especial .git mencionado antes para que nuestro sistema de
archivos no se abarrote (y para que no podamos editar o borrar
accidentalmente una versión anterior).
Ahora supón que Dracula agrega más información al archivo. (Otra vez,
editaremos con nano y luego con cat
mostraremos el contenido del archivo; podrías usar un editor diferente y
no necesitar cat.)
SALIDA
Cold and dry, but everything is my favorite color
The two moons may be a problem for WolfmanCuando ejecutamos git status ahora nos dice que un
archivo ya sabe que ha sido modificado:
SALIDA
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: mars.txt
no changes added to commit (use "git add" and/or "git commit -a")La última línea es la frase clave: “no changes added to commit”.
Hemos cambiado este archivo, pero no le hemos dicho a Git que queremos
que guarde los cambios (lo cual hacemos con git add) ni los
hemos guardado (lo cual hacemos con git commit). Así que
hagamos eso ahora. Es una buena práctica revisar siempre nuestros
cambios antes de guardarlos. Hacemos esto usando git diff.
Esto nos muestra las diferencias entre el estado actual del archivo y la
versión guardada más reciente:
SALIDA
diff --git a/mars.txt b/mars.txt
index df0654a..315bf3a 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1 +1,2 @@
Cold and dry, but everything is my favorite color
+The two moons may be a problem for WolfmanLa salida es críptica porque en realidad es una serie de comandos
para herramientas como editores y patch que les dice cómo
reconstruir un archivo a partir del otro. Si lo dividimos en
secciones:
- La primera línea nos dice que Git está produciendo un
output similar al del comando Unix
diffcomparando las versiones anterior y nueva del archivo. - La segunda línea dice exactamente qué versiones del archivo está
comparando Git;
df0654ay315bf3ason etiquetas únicas generadas por computadora para esas versiones. - Las líneas tercera y cuarta muestran una vez más el nombre del archivo que se está cambiando.
- Las líneas restantes son las más interesantes, ellas nos muestran
las diferencias en cuestión y las líneas donde ellas ocurren. En
particular, el marcador
+en la primera columna muestra dónde agregamos una línea.
Después de revisar nuestro cambio, es tiempo de hacer un commit de eso:
SALIDA
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: mars.txt
no changes added to commit (use "git add" and/or "git commit -a")¡Vaya!: Git no hará commit porque no usamos
git add primero. Arreglemos esto:
SALIDA
[master 34961b1] Add concerns about effects of Mars' moons on Wolfman
1 file changed, 1 insertion(+)Git insiste en que agreguemos archivos al conjunto de cambios que queremos hacer antes de hacer commit de alguna cosa. Esto permite hacer commit de nuestros cambios en etapas y capturarlos en porciones lógicas en lugar de solo lotes grandes. Por ejemplo, supongamos que agregamos algunas citas a una investigación relevante para nuestra tesis. Podríamos querer hacer commit a esas adiciones, y su correspondiente registro bibliográfico, pero no hacer commit del trabajo que estamos haciendo sobre la conclusión (el cual no hemos terminado aún).
Para permitir esto, Git tiene un staging area especial donde mantiene registro de cosas que han sido agregadas al actual changeset pero aún no se han vuelto commit.
Staging Area
Si piensas en Git como tomar instantáneas de cambios durante la vida
de un proyecto, git add especifica qué irá en una
instantánea (poniendo cosas en el staging area), y
git commit entonces realmente toma la instantánea,
y genera un registro permanente de esto (como un
commit). Si no tienes nada en el staging area cuando
escribes git commit, Git te pedirá que uses
git commit -a o git commit --all, ¡Que es como
reunir a todos para la foto! Sin embargo, es casi siempre mejor
agregar explícitamente cosas al staging area, porque
podrías hacer commit de cambios que habías olvidado.
(Volviendo a las instantáneas, podrías capturar al extra con el
maquillaje incompleto caminando en el escenario para la toma porque
usaste -a!) Trata de organizar las cosas manualmente o
podrías encontrarte buscando “deshacer git commit” más de lo que te
gustaría!

Veamos cómo nuestros cambios a un archivo se mueven de nuestro editor al staging area y luego al almacenamiento de largo plazo. Primero, agregamos otra línea al archivo:
SALIDA
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humiditySALIDA
diff --git a/mars.txt b/mars.txt
index 315bf3a..b36abfd 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1,2 +1,3 @@
@@ -1,2 +1,3 @@
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humidityHasta aquí, todo bien: hemos agregado una línea al final del archivo
(mostrado con un + en la primera columna). Ahora pongamos
el cambio en el staging area y veamos lo que reporta
git diff:
No hay output: hasta donde Git puede decir, no hay diferencias entre lo que se pidió guardar permanentemente y lo que actualmente está en el directorio. Sin embargo, si hacemos esto:
SALIDA
diff --git a/mars.txt b/mars.txt
index 315bf3a..b36abfd 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1,2 +1,3 @@
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humidityesto nos muestra la diferencia entre el último cambio que sí hizo commit y lo que está en el staging area. Guardemos nuestros cambios:
SALIDA
[master 005937f] Discuss concerns about Mars' climate for Mummy
1 file changed, 1 insertion(+)revisa nuestro estatus:
SALIDA
On branch master
nothing to commit, working directory cleany mira en la historia lo que hemos hecho hasta aquí:
SALIDA
commit 005937fbe2a98fb83f0ade869025dc2636b4dad5
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 10:14:07 2013 -0400
Discuss concerns about Mars' climate for Mummy
commit 34961b159c27df3b475cfe4415d94a6d1fcd064d
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 10:07:21 2013 -0400
Add concerns about effects of Mars' moons on Wolfman
commit f22b25e3233b4645dabd0d81e651fe074bd8e73b
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 09:51:46 2013 -0400
Start notes on Mars as a baseDiferencias basadas en palabras
A veces, por ejemplo en el caso de documentos de texto, un diff por
líneas es demasiado caótico. Es en ese caso donde la opción
--color-words de git diff se vuelve muy útil
ya que resalta las palabras modificadas usando colores.
Paginación del Registro
Cuando el output de git log es
demasiado largo para caber en tu pantalla, git usa un
programa para dividirlo en páginas del tamaño de tu pantalla. Cuando
este “paginador” es llamado, notarás que la última línea de tu pantalla
es un :, en lugar de tu prompt de siempre.
- Para salir del paginador, presiona
q. - Para moverte a la siguiente página, presiona la barra espaciadora.
- Para buscar
alguna_palabraen todas las páginas, escribe/alguna_palabray navega entre las coincidencias presionandon(next).
Tamaño Límite del Registro
Para evitar que git log cubra toda la pantalla de tu
terminal, puedes limitar el número de commits que Git
lista usando -N, donde N es el número de
commits que quieres ver. Por ejemplo, si sólo quieres
información de el último commit, puedes usar:
SALIDA
commit 005937fbe2a98fb83f0ade869025dc2636b4dad5
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 10:14:07 2013 -0400
Discuss concerns about Mars' climate for MummyPuedes reducir la cantidad de información usando la opción
--oneline:
SALIDA
* 005937f Discuss concerns about Mars' climate for Mummy
* 34961b1 Add concerns about effects of Mars' moons on Wolfman
* f22b25e Start notes on Mars as a baseTambién puedes combinar las opciones --oneline con
otras. Una combinación útil es:
SALIDA
* 005937f Discuss concerns about Mars' climate for Mummy (HEAD, master)
* 34961b1 Add concerns about effects of Mars' moons on Wolfman
* f22b25e Start notes on Mars as a baseDirectorios
Dos hechos importantes que deberías saber acerca de directorios en Git.
- Git no rastrea directorios por sí mismos, sólo los archivos dentro de ellos. Inténtalo tú mismo:
Nota que, nuestro nuevo y vació directorio directory no
aparece en la lista de archivos no rastreados aún si nosotros
explícitamente lo agregamos(via git add) a nuestro
repositorio. Esta es la razón por la que algunas veces verás archivos
.gitkeep en directorios que si no fuera por ello estarían
vacíos. A diferencia de .gitignore, estos archivos no son
especiales y su único propósito es poblar un directorio para que Git lo
agregue al repositorio. En efecto, podrías nombrar estos archivos como
quieras.
{:start=“2”} 2. Si creas un directorio en tu repositorio Git y lo llenas con archivos, podrás agregar todos los archivos en el directorio a la vez haciendo:
Recapitulando, cuando queremos agregar cambios a nuestro repositorio,
primero necesitamos agregar los archivos cambiados al staging
area (git add) y luego hacer un
commit de los cambios al repositorio
(git commit):

Escogiendo un Mensaje para el Commit
¿Cuál de los siguientes mensajes de commit sería el
más apropiado para el último commit hecho a
mars.txt?
- “Changes”
- “Added line ‘But the Mummy will appreciate the lack of humidity’ to mars.txt”
- “Discuss effects of Mars’ climate on the Mummy”
La respuesta 1 no es suficientemente descriptiva, y la respuesta 2 es demasiado descriptiva y redundante, pero la respuesta 3 es buena: corta pero descriptiva.
Haciendo Commit de Cambios a Git
¿Cuál comando(s) de abajo debería guardar los cambios de
myfile.txt a mi repositorio local Git?
$ git commit -m "my recent changes"$ git init myfile.txt$ git commit -m "my recent changes"$ git add myfile.txt$ git commit -m "my recent changes"$ git commit -m myfile.txt "my recent changes"
- Debería crear un commit solamente si los archivos ya han sido agregados al staging area.
- Trataría de crear un nuevo respositorio.
- Es correcto: primero agrega el archivo al staging area, luego hace commit.
- Intentaría hacer commit al archivo “my recent changes” con el mensaje myfile.txt.
Haciendo Commit a Multiples Archivos
El staging area puede tener cambios de cualquier número de archivos a los que quieras hacer commit, como una sóla instantánea.
- Agrega algún texto a
mars.txtanotando tu decisión de considerar Venus como base - Crea un nuevo archivo
venus.txtcon tus pensamientos iniciales acerca de Venus como base para tí y tus amigos - Agrega los cambios de ambos archivos al staging area, y haz un commit de esos cambios.
Primero haremos nuestros cambios a los archivos mars.txt
y venus.txt:
SALIDA
Maybe I should start with a base on Venus.SALIDA
Venus is a nice planet and I definitely should consider it as a base.Ahora puedes agregar ambos archivos al staging area. Podemos hacer esto en una sóla línea:
O con varios comandos:
Ahora los archivos están listos para hacer commit.
Puedes verificar esto usando git status. Si estás lista
para hacer commit usa:
SALIDA
[master cc127c2]
Write plans to start a base on Venus
2 files changed, 2 insertions(+)
create mode 100644 venus.txtRepositorio bio
Challenge
- Crea un nuevo repositorio Git en tu computadora, llamado
bio. - Escribe una autobiografía de tres líneas en un archivo llamado
me.txt, haz commit de tus cambios - Modifica una línea, agrega una cuarta línea
- Muestra las diferencias entre el estado actualizado y el original
Si es necesario, sal de la carpeta planets:
Crea una nueva carpeta llamada bio y ‘navega’ a
ella:
Inicia git:
Crea tu archivo de biografía me.txt usando
nano u otro editor de texto. Una vez hecho, agrega y haz
commit de tu cambio al repositorio:
Modifica el archivo como se describe arriba (modifica una línea,
agrega una cuarta línea). Para mostrar las diferencias entre el estado
actual y el original, usa git diff:
BASH
$ git add me.txt
$ git commit -m "Update Vlad's bio." --author="Frank N. Stein <franky@monster.com>"SALIDA
[master 4162a51] Update Vlad's bio.
Author: Frank N. Stein <franky@monster.com>
1 file changed, 2 insertions(+), 2 deletions(-)SALIDA
commit 4162a51b273ba799a9d395dd70c45d96dba4e2ff
Author: Frank N. Stein <franky@monster.com>
Commit: Vlad Dracula <vlad@tran.sylvan.ia>
Update Vlad's bio.
commit aaa3271e5e26f75f11892718e83a3e2743fab8ea
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Commit: Vlad Dracula <vlad@tran.sylvan.ia>
Vlad's initial bio.-
git statusmuestra el estatus de un repositorio. - Los archivos pueden ser almacenados en un directorio de trabajo del proyecto (el cual ven los usuarios), el staging area (donde el siguiente commit está siendo construido) y el repositorio local (donde los commits son registrados permanentemente).
-
git addpone archivos en el staging area. -
git commitguarda el contenido del staging area como un nuevo commit en el repositorio local. - Siempre escribe un mensaje de registro cuando hagas un commit con cambios.
Content from Explorando el "History"
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 25 minutos
Hoja de ruta
Preguntas
- ¿Cómo puedo identificar versiones anteriores de archivos?
- ¿Cómo puedo revisar mis cambios?
- ¿Cómo puedo recuperar versiones anteriores de archivos?
Objetivos
- Explicar qué es el HEAD de un repositorio y cómo usarlo.
- Identificar y usar el número de commit the Git.
- Comparar varias versiones de archivos.
- Restaurar versiones anteriores de archivos.
Como vimos en la lección anterior, podemos referirnos a los
commits por sus identificadores. Puedes referirte al
commit más reciente del directorio de trabajo usando el
identificador HEAD.
Hemos estado agregando una línea a la vez a mars.txt,
por lo que es fácil rastrear nuestro progreso, así que hagamos eso
usando HEAD. Antes de iniciar, hagamos un cambio en
mars.txt.
SALIDA
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
An ill-considered changeAhora, veamos lo que tenemos.
SALIDA
diff --git a/mars.txt b/mars.txt
index b36abfd..0848c8d 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1,3 +1,4 @@
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
+An ill-considered change.Lo mismo obtendrías si omites HEAD (intentalo). La
verdadera ventaja en todo esto es cuando puedes referirte a
commits previos. Hacemos esto agregando ~1
para referirnos al commit inmediatamente anterior a
HEAD.
Si queremos ver las diferencias entre commits
anteriores podemos usar git diff nuevamente, pero con la
notación HEAD~1,HEAD~2, y así sucesivamente,
para referirse a ellos:
SALIDA
diff --git a/mars.txt b/mars.txt
index df0654a..b36abfd 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1 +1,3 @@
Cold and dry, but everything is my favorite color
+The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humidityTambién podríamos usar git show, que nos muestra qué
cambios hemos realizado en un commit anterior así como
el mensaje del commit, en lugar de las
diferencias entre un commit y nuestro
directorio de trabajo, que vemos usando git diff.
SALIDA
commit 34961b159c27df3b475cfe4415d94a6d1fcd064d
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 10:07:21 2013 -0400
Add concerns about effects of Mars' moons on Wolfman
diff --git a/mars.txt b/mars.txt
index df0654a..315bf3a 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1 +1,2 @@
Cold and dry, but everything is my favorite color
+The two moons may be a problem for WolfmanDe este modo, podemos construir una cadena de
commits. El más reciente de la cadena es referido como
HEAD; podemos referirnos a commits
anteriores utilizando la notación ~, así
HEAD~1 (pronunciado “head minus one”) significa “el commit
anterior”, mientras que HEAD~123 va 123
commits hacia atrás desde donde estamos ahora.
También podemos referirnos a los commits usando esas
largas cadenas de dígitos y letras que git log despliega.
Estos son IDs únicos para los cambios, y aquí “únicos” realmente
significa únicos: cada cambio a cualquier conjunto de archivos en
cualquier computadora tiene un identificador único de 40 caracteres.
Nuestro primer commit recibió el ID
f22b25e3233b4645dabd0d81e651fe074bd8e73b, así que probemos
esto:
SALIDA
diff --git a/mars.txt b/mars.txt
index df0654a..b36abfd 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1 +1,3 @@
Cold and dry, but everything is my favorite color
+The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humidityEsa es la respuesta correcta, pero escribir cadenas aleatorias de 40 caracteres es molesto, entonces Git nos permite usar solo los primeros caracteres:
SALIDA
diff --git a/mars.txt b/mars.txt
index df0654a..b36abfd 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1 +1,3 @@
Cold and dry, but everything is my favorite color
+The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humidity¡Todo bien! Asi que podemos guardar cambios en los archivos y ver qué hemos cambiado —ahora ¿Cómo podemos restaurar versiones anteriores de las cosas? Supongamos que accidentalmente sobrescribimos nuestro archivo:
SALIDA
We will need to manufacture our own oxygengit status ahora nos dice que el archivo ha sido
cambiado, pero esos cambios no se han organizado:
SALIDA
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: mars.txt
no changes added to commit (use "git add" and/or "git commit -a")Podemos volver a poner las cosas tal como estaban usando
git checkout:
SALIDA
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidityComo puedes adivinar por su nombre, git checkout
recupera (es decir, restaura) una versión anterior de un archivo. En
este caso, le estamos diciendo a Git que queremos recuperar la versión
del archivo grabado en HEAD, que es el último
commit guardado. Si queremos volver más allá, podemos
usar un identificador de commit en su lugar:
SALIDA
Cold and dry, but everything is my favorite colorSALIDA
# On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: mars.txt
#
no changes added to commit (use "git add" and/or "git commit -a")Ten en cuenta que los cambios están en el staging
area de almacenamiento. Nuevamente, podemos volver a poner las
cosas tal como estaban usando git checkout:
No pierdas tu HEAD
Arriba usamos
para revertir mars.txt a su estado después del
commit f22b25e. Pero ¡Ten cuidado! El
comando checkout tiene otras funcionalidades importantes y
Git puede malinterpretar tus intenciones si > no sos precisa a la
hora de tipear. Por ejemplo, si olvidas mars.txt en ese
comando, Git te dirá que “You are in ‘detached HEAD’ state”. En este
estado, no deberías hacer ningún cambio. Puedes arreglar esto volviendo
a conectar tu head usando
git checkout master
Es importante recordar que debemos usar el número de
commit que identifica el estado del repositorio
antes del cambio que intentamos deshacer. Un error común es
usar el número de commit en el cual hicimos el cambio
del cual nos estamos tratando de deshacer. En el siguiente ejemplo,
queremos recuperar el estado antes del más reciente
commit (HEAD~1), que es
commit f22b25e:

Así que, para poner todo junto, aqui esta como Git trabaja, en forma de dibujo:

Simplificando el caso común
Si lees el output de git status
detenidamente, verás que incluye esta sugerencia:
Como deciamos, git checkout sin un identificador de
versión restaura los archivos al estado guardado en HEAD.
El doble guión -- es necesario para separar los nombres de
los archivos que se están recuperando del comando mismo: sin esto, Git
intentaría usar el nombre del archivo como el identificador del
commit.
El hecho de que los archivos puedan revertirse uno por uno tiende a cambiar la forma en que las personas organizan su trabajo. Si todo está en un documento grande, es difícil (pero no imposible) deshacer cambios a la introducción sin deshacer los cambios posteriores a la conclusión. Si la introducción y la conclusión se almacenan en archivos separados, por otra parte, retroceder y avanzar en el tiempo se vuelve mucho más fácil.
Recuperando versiones anteriores de un archivo
Jennifer ha realizado cambios en el script de Python en el que ha estado trabajando durante semanas, y las modificaciones que hizo esta mañana “corrompieron” el script y ya no funciona. Ella ha pasado ~ 1hr tratando de solucionarlo, sin tener suerte…
Por suerte, ¡Ella ha estado haciendo un seguimiento de las versiones
de su proyecto usando Git! ¿Cuáles comandos le permitirán recuperar la
última versión estable de su script Python llamado
data_cruncher.py?
$ git checkout HEAD$ git checkout HEAD data_cruncher.py$ git checkout HEAD~1 data_cruncher.py$ git checkout <unique ID of last commit> data_cruncher.pyAmbos 2 y 4
Revertir un commit
Jennifer está colaborando en su script de Python con
sus colegas y se da cuenta que su último commit en el
repositorio del grupo es incorrecto y quiere deshacerlo. Jennifer
necesita deshacer correctamente para que todos en el repositorio del
grupo tengan el cambio correcto.
git revert [ID de commit incorrecto] hará un nuevo
commit que va a deshacer el commit anterior erroneo de
Jennifer. Por lo tanto, git revert es diferente de
git checkout [commit ID] porque checkout es
para cambios locales no comprometidos con el repositorio de grupo. A
continuación se encuentran los pasos correctos y explicaciones para que
Jennifer use git revert, ¿Cuál es el comando que falta?
________ # Mira el historial de git del proyecto para encontrar el ID del commit
Copia el ID (los primeros caracteres del ID, por ejemplo 0b1d055).
git revert [commit ID]Escriba el nuevo mensaje del commit.
Salva y cierra
Entendiendo Workflow y History
¿Cuál es el output de cat venus.txt al final de este conjunto de comandos?
BASH
$ cd planets
$ nano venus.txt #captura el siguiente texto: Venus is beautiful and full of love
$ git add venus.txt
$ nano venus.txt #agrega el siguiente texto: Venus is too hot to be suitable as a base
$ git commit -m "Comment on Venus as an unsuitable base"
$ git checkout HEAD venus.txt
$ cat venus.txt #esto imprimirá el contenido de venus.txt en la pantallaSALIDA
Venus is too hot to be suitable as a baseSALIDA
Venus is beautiful and full of loveSALIDA
Venus is beautiful and full of love
Venus is too hot to be suitable as a baseSALIDA
Error because you have changed venus.txt without committing the changesVamos línea por línea
Entra al directorio ‘planets’
Creamos un nuevo archivo y escribimos una oración, pero el archivo no es rastreado por git.
Ahora el archivo está en escena. Los cambios que se han realizado en el archivo hasta ahora se confirmarán en el siguiente commit.
El archivo ha sido modificado. Los nuevos cambios no se realizan porque no hemos agregado el archivo.
Los cambios que se incluyeron (Venus is beautiful and full of love) se han confirmado. Los cambios que no se realizaron (Venus is too hot to be suitable as a base) no. Nuestra copia de trabajo local es diferente a la copia en nuestro repositorio local.
Con el checkout, descartamos los cambios en el directorio de trabajo para que nuestra copia local sea exactamente la misma que nuestra HEAD, el más reciente commit.
Si imprimimos venus.txt obtendremos la respuesta 2.
Comprobando lo que entendiste de
git diff
Considera este comando: git diff HEAD~3 mars.txt. ¿Qué
predices que hará este comando si lo ejecutas? ¿Qué sucede cuando lo
ejecutas? ¿Por qué?
Prueba éste otro comando, git diff [ID] mars.txt, donde
[ID] es el identificador único para tu commit más reciente. ¿Qué piensas
tú que sucederá, y qué es lo que pasa?
Deshacer los cambios almacenados
git checkout puede usarse para restaurar un
commit anterior cuando cambios no marcados se han
hecho, pero ¿También funcionará para los cambios que se han marcado pero
no se han vuelto commit? Haz un cambio a
mars.txt, agrega el cambio y usagit checkout
para ver si puedes eliminar tu cambio.
Explorar y resumir el History
Explorar el history es una parte importante de git, a menudo es un desafío encontrar el ID de confirmación correcto, especialmente si el commit es de hace varios meses.
Imagina que el proyecto planets tiene más de 50
archivos. Deseas encontrar un commit con texto
específico en mars.txt. Cuando escribes
git log, aparece una lista muy larga, ¿Cómo puede
restringir la búsqueda?
Recuerda que el comando git diff nos permite explorar un
archivo específico, por ejemplo git diff mars.txt. Podemos
aplicar una idea similar aquí.
Desafortunadamente, algunos de estos mensajes en los
commits son muy ambiguos, por ejemplo
update files. ¿Cómo puedes buscar a través de estos
archivos?
Tanto git diff como git log son muy útiles
y resumen una parte diferente del history para ti. ¿Es
posible combinar ambos? Vamos a intentar lo siguiente:
Deberías obtener una larga lista de output, y deberías poder ver tanto los dos mensajes del commit como la diferencia entre cada commit.
Pregunta: ¿Qué hace el siguiente comando?
-
git diffdespliega diferencias entre commits. -
git checkoutrecupera versiones anteriores de archivos.
Content from Ignorando cosas
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 5 minutos
Hoja de ruta
Preguntas
- ¿Cómo puedo indicarle a Git que ignore los archivos que no quiero rastrear?
Objetivos
- Configure Git para ignorar archivos específicos.
- Explica por qué ignorar los archivos puede ser útil.
¿Qué pasa si tenemos archivos que no queremos que Git rastree, como archivos de copia de seguridad creados por nuestro editor o archivos intermedios creados durante el análisis de datos? Vamos a crear algunos archivos ficticios:
Mira lo que Git dice:
SALIDA
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
a.dat
b.dat
c.dat
results/
nothing added to commit but untracked files present (use "git add" to track)Colocar estos archivos bajo el control de versiones sería un desperdicio de espacio en disco. Y lo que es peor, al tenerlos todos listados, podría distraernos de los cambios que realmente importan, así que vamos a decirle a Git que los ignore.
Lo hacemos creando un archivo en el directorio raíz de nuestro
proyecto llamado .gitignore:
SALIDA
*.dat
results/Estos patrones le dicen a Git que ignore cualquier archivo cuyo
nombre termine en .dat y todo lo que haya en el directorio
results. (Si alguno de estos archivos ya estaba siendo
rastreado, Git seguirá rastreándolos.)
Una vez que hemos creado este archivo, la salida de
git status es mucho más limpia:
SALIDA
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
nothing added to commit but untracked files present (use "git add" to track)Lo único que Git advierte ahora, es el archivo
.gitignore recién creado. Podrías pensar que no queremos
rastrearlo, pero todos aquellos con los que compartimos nuestro
repositorio probablemente desearán ignorar las mismas cosas que
nosotros. Vamos a agregar y hacer “commit” de
.gitignore:
SALIDA
# On branch master
nothing to commit, working directory cleanComo ventaja, usar .gitignore nos ayuda a evitar agregar
accidentalmente al repositorio los archivos que no queremos
rastrear:
SALIDA
The following paths are ignored by one of your .gitignore files:
a.dat
Use -f if you really want to add them.Si realmente queremos anular la configuración de ignorar, podemos
usar git add -f para obligar a Git a añadir algo. Por
ejemplo, git add -f a.dat. También podemos ver siempre el
estado de los archivos ignorados si queremos:
SALIDA
On branch master
Ignored files:
(use "git add -f <file>..." to include in what will be committed)
a.dat
b.dat
c.dat
results/
nothing to commit, working directory cleanComo ocurre con la mayoría de los problemas de programación, hay
varias maneras de resolver esto. Si sólo deseas ignorar el contenido de
results/plots, puedes cambiar tu .gitignore
para ignorar solamente la subcarpeta /plots/ añadiendo la
siguiente línea a su .gitignore:
results/plots/
Si, en cambio, deseas ignorar todo en /results/, pero
deseas realizar el seguimiento de results/data, puedes
agregar results/ a su .gitignore y crear una excepción para
la carpeta results/data/. El siguiente reto cubrirá este
tipo de solución.
A veces el patrón ** viene muy bien para referirse a
múltiples niveles de directorio. E.g. **/results/plots/*
hará que git ignore el directorio results/plots en
cualquier directorio raíz.
Incluyendo archivos específicos
¿Cómo ignorarías todos los archivos .data en tu
directorio raíz, exceptofinal.data? Sugerencia: Descubre lo
que ! (el signo de exclamación) hace
Ignorando todos los archivos de datos en un directorio
Dado un directorio con la siguiente estructura:
BASH
results/data/position/gps/a.data
results/data/position/gps/b.data
results/data/position/gps/c.data
results/data/position/gps/info.txt
results/plots¿Cuál es la regla más corta en .gitignore para ignorar
todos los archivos .data en
result/data/position/gps? No ignores el archivo
info.txt.
Agregando results/data/position/gps/*.data coincidirá
con cada archivo en results/data/position/gps que termine
con .data. El archivo
results/data/position/gps/info.txt no será ignorado.
El modificador ! anulará algún patrón ignorado
previamente definido. Debido a que la entrada !*.data anula
todos los archivos.data anteriores en
.gitignore, ninguno de ellos será ignorado, y todos los
archivos.data serán rastreados.
Archivos de bitácora
Supón que escribiste un script que crea muchos
archivos de registro con la estructura log_01,
log_02, log_03, etc. Deseas conservarlos pero
no rastrearlos a través de git.
Escribe una entrada en tu archivo
.gitignoreque excluya los archivos con estructuralog_01,log_02, etc.Prueba tu “patrón de ignorar” creando algunos archivos ficticios
log_01, etc.Te das cuenta de que el archivo
log_01es muy importante después de todo, así que lo tienes que agregar a los archivos rastreados sin cambiar el.gitignorede nuevoDiscute con tu compañero de a lado qué otros tipos de archivos podrían residir en tu directorio que no deseas seguir y por tanto excluir a través de
.gitignore.
- Agrega
log_*olog*como nueva entrada en tu archivo .gitignore - Rastrea
log_01usandogit add -f log_01
- El archivo
.gitignorele dice a Git qué archivos ignorar.
Content from Repositorios remotos en GitHub
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 30 minutos
Hoja de ruta
Preguntas
- ¿Cómo puedo compartir los cambios con otros en la web?
Objetivos
- Explica qué es un repositorio remoto y por qué es útil.
- Hacer push y pull en un repositorio remoto
Cuando se trabaja en colaboración con otras personas es cuando el sistema de control de versiones alcanza su pleno potencial. Ya hemos visto la mayor parte de las herramientas que necesitamos para ello, tan sólo nos falta ver cómo copiar los cambios realizados de un repositorio a otro.
Sistemas como Git ya nos permiten mover el trabajo realizado entre dos repositorios cualesquiera. Sin embargo, en la práctica es más sencillo establecer uno de ellos como repositorio central y tenerlo en la red en lugar de tu computadora particular. La mayoría de desarrolladores usan servicios de alojamiento en la red, tales como GitHub, BitBucket o GitLab, para alojar ese repositorio central; en la última sección de esta lección exploraremos los pros y los contras de cada uno de ellos.
Empecemos por compartir con todos los demás los cambios que hemos
realizado en nuestro proyecto actual. Para ello, ingresa en tu cuenta de
GitHub y haz click en el icono que hay en la esquina superior derecha
para crear un nuevo repositorio llamado planets:
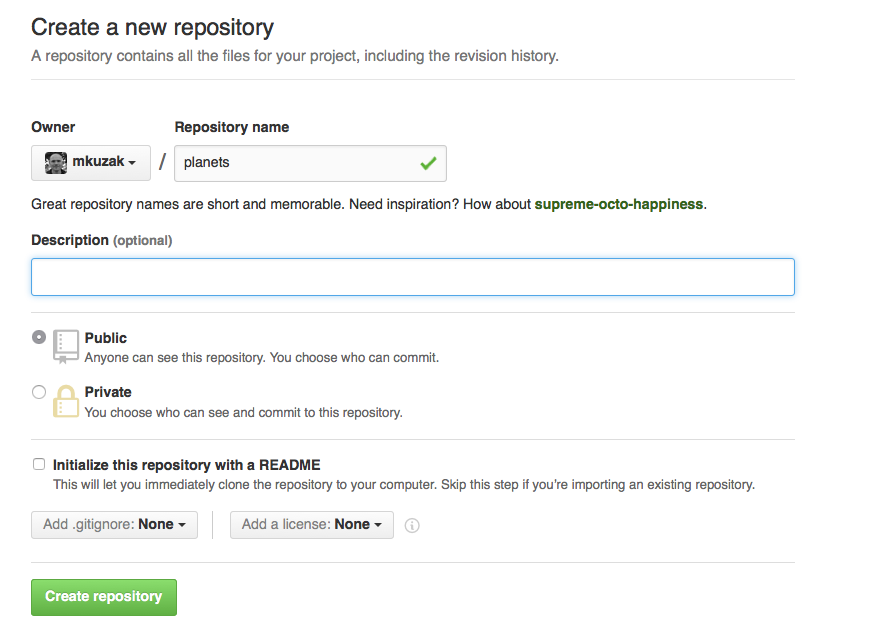
Dale a tu repositorio el nombre “planets” y haz click en “Create repository”:
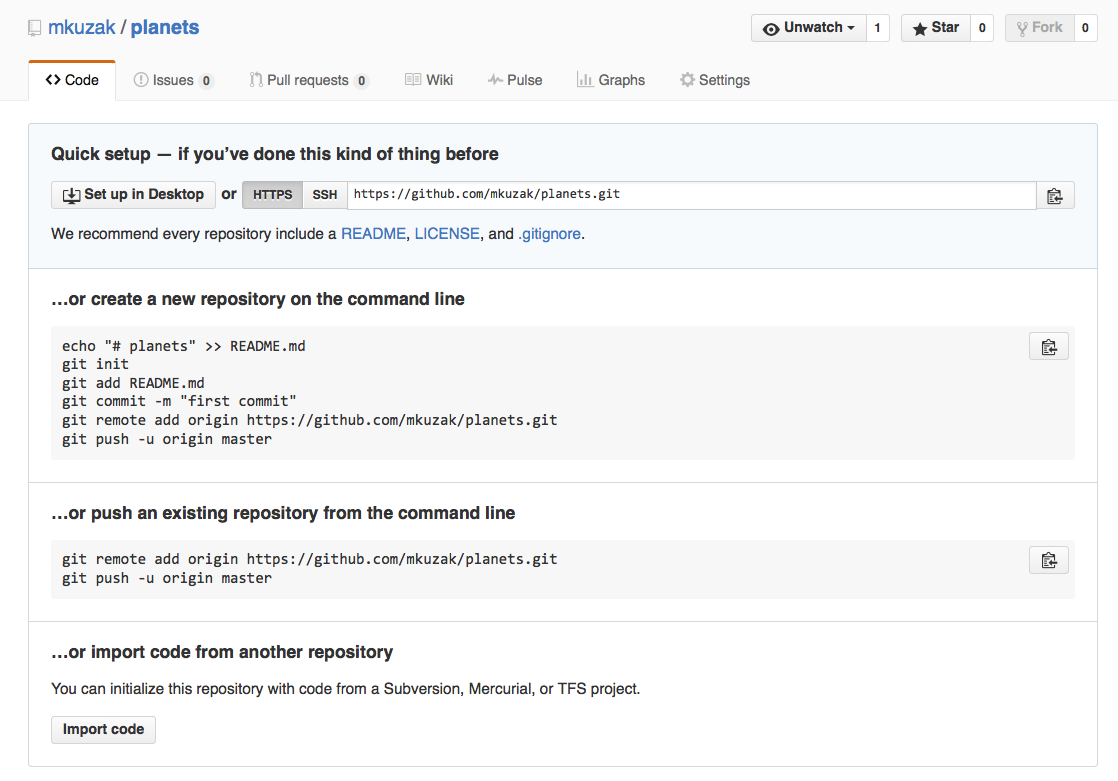
Tan pronto es creado el repositorio, GitHub muestra una página con una URL y algo de información sobre cómo configurar tu repositorio local.
Esto en realidad ejecuta lo siguiente en los servidores de GitHub:
Nuestro repositorio local contiene nuestro trabajo previo en
mars.txt, pero el repositorio remoto en GitHub todavía no
contiene ningún archivo:

El siguiente paso es conectar los dos repositorios. Ello se consigue convirtiendo al repositorio en GitHub en un repositorio remoto del repositorio local. La página de inicio del repositorio en GitHub incluye la secuencia de caracteres que necesitamos para identificarlo:

Haz click en el enlace ‘HTTPS’ para cambiar el protocolo de SSH a HTTPS.
HTTPS vs. SSH
Usamos aquí HTTPS porque no necesita ninguna configuración adicional. Si en el curso quieres configurar el acceso mediante SSH, que es un poco más seguro, puedes seguir cualquiera de los excelentes tutoriales que existen en GitHub, Atlassian/BitBucket y GitLab (este último con capturas animadas de pantalla).

Copia dicha URL desde el navegador, ve al repositorio local
planets y ejecuta allí este comando:
Asegúrate de usar la URL de tu repositorio en lugar de la de vlad: la
única diferencia debería ser tu nombre de usuario en lugar de
vlad.
Podemos comprobar que el comando ha funcionado bien ejecutando
git remote -v:
SALIDA
origin https://github.com/vlad/planets.git (push)
origin https://github.com/vlad/planets.git (fetch)El nombre origin es un apodo local para tu repositorio
remoto. Se puede usar cualquier otro nombre si se desea, pero
origin es la elección más habitual.
Una vez seleccionado el apodo local origin, el siguiente
comando enviará los cambios realizados en nuestro repositorio local al
repositorio en GitHub:
SALIDA
Counting objects: 9, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (6/6), done.
Writing objects: 100% (9/9), 821 bytes, done.
Total 9 (delta 2), reused 0 (delta 0)
To https://github.com/vlad/planets
* [new branch] master -> master
Branch master set up to track remote branch master from origin.Proxy
Si la red a la que estás conectado usa un proxy es posible que tu último comando fallara con el siguiente mensaje de error: “Could not resolve hostname”. Para solucionarlo es necesario informar a Git sobre el proxy:
BASH
$ git config --global http.proxy http://user:password@proxy.url
$ git config --global https.proxy http://user:password@proxy.urlSi después te conectas a otra red que no usa un proxy es necesario decirle a Git que deshabilite el proxy:
Gestores de contraseñas
Si tu sistema operativo tiene un gestor de contraseñas configurado,
git push intentará usarlo cuando necesite un nombre de
usuario y contraseña. Al menos ese es el comportamiento por defecto para
Git.language-bash en Windows. Si quieres que haya que introducir el
nombre de usuario y contraseña en la terminal, en lugar de usar el
gestor de contraseñas, hay que ejecutar el siguiente comando en la
terminal antes de lanzar git push:
A pesar de lo que se podría deducir por el nombre, git
usa SSH_ASKPASS para todas las peticiones de
credenciales, tanto si se está usando git vía SSH como si se está
usando vía https, por lo que es posible que quieras deshabilitarlo en
ambos casos con unset SSH_ASKPASS .
Otra alternativa es añadir unset SSH_ASKPASS al final de
tu ~/.bashrc para que git use por defecto la terminal para
los nombres de usuario y las contraseñas.
Nuestros repositorios local y remoto se encuentran ahora en el siguiente estado:

La opción ‘-u’
En la documentación puedes ver que en ocasiones se usa la opción
-u con el comando git push. Esta opción es
sinónimo de la opción --set-upstream-to para el comando
git branch y se usa para asociar el branch
actual con un branch remoto, de modo que el comando
git pull pueda usarse sin argumentos. Para hacer esto
simplemente ejecuta git push -u origin master una vez que
el repositorio remoto haya sido creado.
También podemos hacer pull, es decir, traernos cambios desde el repositorio remoto al repositorio local:
SALIDA
From https://github.com/vlad/planets
* branch master -> FETCH_HEAD
Already up-to-date.En este caso, hacer pull no ha tenido ningún efecto porque los dos repositorios están ya sincronizados. Por el contrario, si alguien antes hubiera subido con push algunos cambios al repositorio en GitHub, este comando los habría incorporado a nuestro repositorio local.
Interfaz gráfica de GitHub
Navega hasta tu repositorio planets en GitHub. En la
pestaña Code, localiza el texto “XX commits” (donde “XX” es algún
número) y haz click en él. Mueve el cursor sobre los tres botones que
hay a la derecha de cada commit, y haz click en ellos.
¿Qué información puedes obtener/explorar con estos botones? ¿Cómo
obtendrías la misma información en la terminal?
El botón más a la izquierda (con el dibujo de un portapapeles) sirve
para copiar en el portapapeles el identificador completo del
commit en cuestión. En la terminal,
git log muestra los identificadores completos de cada
commit.
Haciendo click en el botón de en medio, se pueden ver todos los
cambios efectuados con el commit en cuestión. Las
líneas verdes sombreadas indican adiciones y las rojas eliminaciones. En
la terminal se puede ver lo mismo con git diff. En
particular, git diff ID1..ID2 donde ID1 y ID2 son
identificadores de commits
(e.g. git diff a3bf1e5..041e637) mostrará las diferencias
entre esos dos commits.
El botón más a la derecha permite ver todos los archivos que existían
en el repositorio en el momento del commit en cuestión.
Para ver lo mismo en la terminal sería necesario hacer
checkout del repositorio a ese momento del tiempo. Para
ello se ejecutaría git checkout ID donde ID es el
identificador del commit que queremos investigar. ¡Si
se hace esto hay que acordarse luego de poner el repositorio de nuevo en
el estado correcto!
Fecha y Hora en GitHub
Crea un repositorio remoto en GitHub. Haz push de los contenidos de tu repositorio local al remoto. Haz cambios en tu repositorio local y haz push de dichos cambios. Ve al repo recién creado en GitHub y comprueba las fechas y horas, también llamadas timestamps de los ficheros. ¿Cómo registra GitHub los tiempos, y por qué?
Github muestra los tiempos en formato relativo legible para los humanos (i.e. “22 hours ago” or “three weeks ago”). Sin embargo, si mueves el cursor sobre un timestamp, podrás ver el tiempo exacto en el que se realizó el último cambio al fichero.
Push vs. Commit
En esta lección hemos introducido el comando “git push”. ¿En qué se diferencia “git push” de “git commit”?
Cuando enviamos cambios con push, estamos interaccionando con un repositorio remoto para actualizarlo con los cambios que hemos hecho localmente (a menudo esto supone compartir con otros los cambios realizados). Por el contrario, commit únicamente actualiza tu repositorio local.
Corrigiendo ajustes en el repositorio remoto
Es muy frecuente cometer un error al especificar la URL del repositorio remoto. Este ejercicio trata de cómo corregir este tipo de errores. Empecemos por añadir un repositorio remoto con una URL inválida:
¿Obtienes un error al añadir el repositorio remoto? ¿Se te ocurre
algún comando que hiciera obvio que la URL de tu repositorio remoto no
es válida? ¿Se te ocurre cómo corregir la URL? (pista: usa
git remote -h). No olvides eliminar este repositorio remoto
una vez que hayas terminado este ejercicio.
No aparece ningún error cuando añadimos el repositorio remoto (añadir
un repositorio remoto informa a git sobre dicho repositorio, pero no
intenta usarlo todavía). Sí veremos un error en cuanto intentemos usarlo
con git push. El comando git remote set-url
nos permite cambiar la URL del repositorio remoto para corregirla.
Licencia GitHub y ficheros README
En esta sección hemos aprendido cómo crear un repositorio remoto en GitHub, pero cuando lo hicimos no añadimos ningún fichero README.md ni ningún fichero de licencia. Si lo hubiéramos hecho, ¿qué crees que habría sucedido cuando intentaste enlazar tus repositorios local y remoto?
En este caso, puesto que ya teníamos un fichero README en nuestro propio repositorio (local), habríamos visto un conficto de unión, conocido como merge conflict (que es cuando git se da cuenta de que hay dos versiones de un mismo fichero y nos pide que resolvamos las diferencias).
- Un repositorio Git local puede ser conectado a uno o más repositorios remotos.
- Usa el protocolo HTTPS para conectarte a un repositorio remoto hasta que hayas aprendido como hacerlo con SSH.
-
git pushcopia los cambios desde el repositorio local a un repositorio remoto. -
git pullcopia los cambios desde un repositorio remoto a un repositorio local.
Content from Trabajos en colaboración
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 5 minutos
Hoja de ruta
Preguntas
- ¿Cómo puedo usar el control de versiones para colaborar con otras personas?
Objetivos
- Clonar un repositorio remoto.
- Colaborar en crear un repositorio común.
Para el siguiente paso, formen parejas. Una persona será el “dueño” y la otra el “colaborador”. El objetivo es que el colaborador agregue cambios al repositorio del dueño. Vamos a cambiar roles al final, de modo que ambas personas puedan participar como dueño y colaborador
Practicando por tu cuenta
Si estás trabajando en esta lección por tu cuenta, puedes hacerlo abriendo una segunda sesión en la ventana de la terminal. Esta ventana representará a tu compañero trabajando en otra computadora. No necesitas darle acceso a nadie en GitHub, pues tú serás ambos “compañeros”.
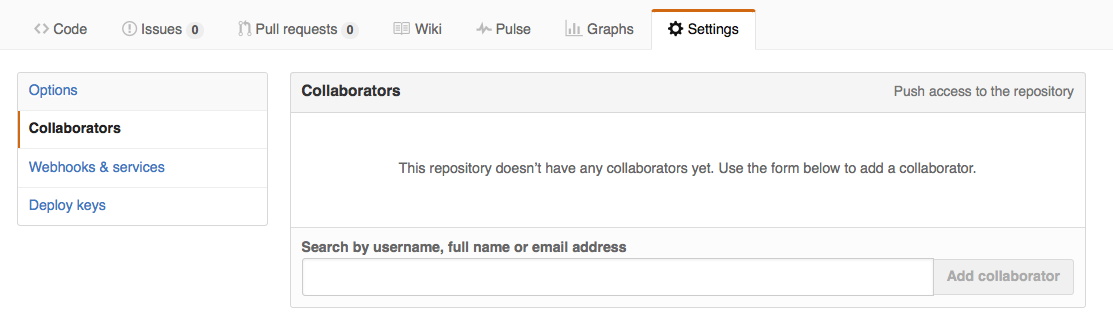
El dueño debe dar acceso al colaborador. En GitHub, haz clic en el botón de configuración arriba a la derecha, luego selecciona “Collaborators” e ingresa el nombre de tu colaborador.
Para aceptar la invitación de acceso al repositorio, el colaborador debe ingresar a https://github.com/notifications. Una vez allí, se puede aceptar la invitación a dicho repositorio.
Luego, el colaborador debe descargar una copia del repositorio del
dueño a su máquina. Esto se conoce como “clonar un repositorio”. Para
clonar el repositorio del dueño en su carpeta de Desktop,
el colaborador debe ejecutar las siguientes líneas:
Reemplaza ‘vlad’ con el nombre de usuario del dueño.

El colaborador puede ahora hacer cambios en la versión clonada del repositorio del dueño, en la misma forma en que se hacían previamente:
SALIDA
It is so a planet!SALIDA
1 file changed, 1 insertion(+)
create mode 100644 pluto.txtLuego enviar los cambios hacia el repositorio del dueño en GitHub haciendo push:
SALIDA
Counting objects: 4, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 306 bytes, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/vlad/planets.git
9272da5..29aba7c master -> masterNota que no es necesario crear un directorio remoto llamado
origin: Git utiliza este nombre de manera automática cuando
clonamos un repositorio. (Esta es la razón por la cual
origin era una opción sensata a la hora de configurar
directorios remotos a mano).
Ahora echa un vistazo al repositorio del dueño en su sitio de Github (quizá debas actualizar la página). Deberás ver el nuevo commit hecho por el colaborador.
Para descargar los cambios hechos por el colaborador desde GitHub, el dueño debe correr las siguientes líneas:
SALIDA
remote: Counting objects: 4, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 0), reused 3 (delta 0)
Unpacking objects: 100% (3/3), done.
From https://github.com/vlad/planets
* branch master -> FETCH_HEAD
Updating 9272da5..29aba7c
Fast-forward
pluto.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 pluto.txtAhora hay tres repositorios sincronizados (el local del dueño, el local del colaborador y el del dueño en GitHub).
Un flujo de trabajo colaborativo básico
Es considerado buena práctica estar seguro de que tienes una versión
actualizada del repositorio en el que colaboras. Para ello deberías
hacer un git pull antes de hacer cambios. El enfoque
sería:
- actualizar el repositorio local
git pull origin master, - realizar cambios
git add, - realizar un commit
git commit -m, y - cargar las actualizaciones a GitHub con
git push origin master
Es mejor hacer varias actualizaciones pequeñas que un commit grande con cambios enormes. Commits pequeños son más fáciles de leer y revisar.
Cambiar roles
Cambien los roles y repitan todo el proceso.
Revisar Cambios
El dueño hace un push de los commits al repositorio sin dar información al colaborador. ¿Cómo puede éste saberlo desde la linea de comandos y desde GitHub?
Challenge
En la linea de comandos, el colaborador puede usar
git fetch origin master para acceder a los cambios remotos
en el repositorio local, sin hacer un merge. Luego,
corriendo git diff master origin/master, el colaborador
verá los cambios en la terminal.
En GitHub, el colaborador puede realizar su propio fork y hallar la barra gris que indica “This branch is 1 commit behind Our-Respository:master.”. Lejos, a la derecha de la barra gris, hay un link para comparar. En la página para comparar, el colaborador debe cambiar el fork hacia su propio repositorio, luego hacer click en el link para “comparar entre forks” y, finalmente, cambiar el fork al repositorio principal. Esto mostrará todos los commits que sean distintos.
Comentar cambios en GitHub
El colaborador podría tener algunas preguntas sobre cambios en una línea hechos por el dueño.
Con GitHub, es posible comentar la diferencia en un commit. Sobre la línea de código a comentar aparece un botón azul para abrir una ventana.
El colaborador puede escribir sus comentarios y sugerencias usando la interfaz de GitHub.
Historial de versiones, backup y control de versiones
Algunos softwares que permiten hacer backups también permiten guardar un historial de versiones y recuperar versiones específicas. ¿Cómo es esta funcionalidad distinta del control de versiones? ¿Cuáles son los beneficios de usar control de versiones, Git y GitHub?
-
git clonecopia un repositorio remoto para crear un repositorio local llamadooriginconfigurado automáticamente.
Content from Conflictos
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 15 minutos
Hoja de ruta
Preguntas
- ¿Qué hago cuando mis cambios entran en conflicto con los de otra persona?
Objetivos
- Explicar qué son los conflictos y cuándo pueden ocurrir.
- Resolver conflictos que resultan de una fusión.
Tan pronto como podemos trabajar en paralelo, es probable que alguien deshaga lo que otro hizo. Esto incluso es probable con una única persona: si estamos trabajando en un software al mismo tiempo en nuestra computadora portátil y un servidor en el laboratorio, podríamos hacer cambios diferentes a cada copia del trabajo. El control de versiones nos ayuda a manejar estos confictos al darnos herramientas para resolver cambios que se hayan sobrepuesto.
Para ver cómo podemos resolver conflictos, primero debemos crear uno.
Actualmente, el archivo mars.txt se ve de la siguiente
manera en dos copias de diferentes compañeros en nuestro repositorio
planetas:
SALIDA
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidityAgreguemos una línea únicamente a la copia de uno de los dos compañeros:
SALIDA
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
This line added to Wolfman's copyy luego hacer push al cambio en GitHub:
SALIDA
[master 5ae9631] Add a line in our home copy
1 file changed, 1 insertion(+)SALIDA
Counting objects: 5, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 352 bytes, done.
Total 3 (delta 1), reused 0 (delta 0)
To https://github.com/vlad/planets
29aba7c..dabb4c8 master -> masterAhora haremos que el otro compañero haga un cambio diferente a su copia sin actualizar desde GitHub:
SALIDA
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
We added a different line in the other copyPodemos hacer commit del cambio localmente
SALIDA
[master 07ebc69] Add a line in my copy
1 file changed, 1 insertion(+)pero Git no nos dejará hacer push en GitHub:
SALIDA
To https://github.com/vlad/planets.git
! [rejected] master -> master (non-fast-forward)
error: failed to push some refs to 'https://github.com/vlad/planets.git'
hint: Updates were rejected because the tip of your current branch is behind
hint: its remote counterpart. Merge the remote changes (e.g. 'git pull')
hint: before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
Git detecta que los cambios hechos en una copia se sobreponen con los
cambios hechos en la otra y nos impide destruir nuestro trabajo previo.
Lo que debemos hacer es traer -pull- los cambios desde
GitHub, unirlos dentro de la copia
en la que estamos trabajando actualmente, y luego hacer
push al resultado. Empecemos haciendo pull a
lo siguiente:
SALIDA
remote: Counting objects: 5, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 1), reused 3 (delta 1)
Unpacking objects: 100% (3/3), done.
From https://github.com/vlad/planets
* branch master -> FETCH_HEAD
Auto-merging mars.txt
CONFLICT (content): Merge conflict in mars.txt
Automatic merge failed; fix conflicts and then commit the result.git pull nos dice que hay un conflicto, y marca ese
conflicto en el archivo afectado:
SALIDA
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
<<<<<<< HEAD
We added a different line in the other copy
=======
This line added to Wolfman's copy
>>>>>>> dabb4c8c450e8475aee9b14b4383acc99f42af1dNuestro cambio —señalado en HEAD— es precedido por
<<<<<<<. Luego, Git insertó
======= como un separador entre los cambios conflictivos y
marcó el fin del contenido descargado desde GitHub con
>>>>>>>. (El código de letras y
números luego del marcador identifica el commit que
acabamos de descargar.)
Ahora debemos editar este archivo para eliminar estos marcadores y reconciliar los cambios. Podemos hacer lo que queramos: mantener el cambio hecho en el repositorio local, mantener el cambio hecho en el repositorio remoto, redactar algo nuevo para reemplazar ambos, o eliminar el cambio completamente. Reemplacemos ambos de manera que el archivo quede así:
SALIDA
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
We removed the conflict on this linePara finalizar la unión, agregamos mars.txt a los
cambios hechos por el merge y luego hacemos
commit:
SALIDA
On branch master
All conflicts fixed but you are still merging.
(use "git commit" to conclude merge)
Changes to be committed:
modified: mars.txt
SALIDA
[master 2abf2b1] Merge changes from GitHubAhora podemos hacer push a nuestros cambios en GitHub:
SALIDA
Counting objects: 10, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (6/6), done.
Writing objects: 100% (6/6), 697 bytes, done.
Total 6 (delta 2), reused 0 (delta 0)
To https://github.com/vlad/planets.git
dabb4c8..2abf2b1 master -> masterGit lleva el registro de qué hemos unificado con qué, de manera que no debemos arreglar las cosas a mano nuevamente cuando el colaborador que hizo el primer cambio hace pull de nuevo:
SALIDA
remote: Counting objects: 10, done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 6 (delta 2), reused 6 (delta 2)
Unpacking objects: 100% (6/6), done.
From https://github.com/vlad/planets
* branch master -> FETCH_HEAD
Updating dabb4c8..2abf2b1
Fast-forward
mars.txt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)Obtenemos el archivo unificado:
SALIDA
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
We removed the conflict on this lineNo es necesario unificar el contenido nuevamente porque Git sabe que alguien ya ha hecho eso.
La habilidad de Git de resolver conflictos es muy útil, pero la resolución de conflictos cuesta tiempo y esfuerzo, y puede introducir errores si los conflictos no son resueltos correctamente. Si te encuentras resolviendo muchos conflictos en un proyecto ten en cuenta estas aproximaciones técnicas para reducirlas:
- Hacer pull con mayor frecuencia, especialmente antes de empezar una nueva tarea
- Usar ramas temáticas para separar trabajo, uniéndolas a la rama
principal -
master- cuando estén completas - Hacer comentarios más cortos y concisos
- Cuando sea apropiado, dividir archivos grandes en varios pequeños de manera que sea menos probable que dos autores alteren el mismo archivo simultáneamente
Los conflictos también pueden ser minimizados con estrategias de administración de proyectos:
- Aclarar con tus colaboradores quién es responsable de cada área
- Discutir con tus colaboradores en qué orden deben realizarse las tareas para que las tareas que puedan cambiar las mismas líneas no se trabajen simultáneamente.
- Si los conflictos son de estilo (e.g. tabulaciones vs. espacios),
establecer una convención que rija el proyecto y utilizar herramientas
de estilo de código (e.g.
htmltidy,perltidy,rubocop, etc.) para forzarlas, si es necesario
Solucionando conflictos creados por ti
Clona el repositorio creado por tu instructor. Agrégale un nuevo archivo y modificar un archivo existente (tu instructor te dirá cuál). Cuando tu instructor te lo pida, trae los cambios -haciendo pull- desde el repositorio para crear un conflicto, y luego resuélvelo.
Conflictos en archivos no textuales
¿Qué hace Git cuando hay un conflicto en una imagen u otro archivo no de texto que está almacenado con control de versiones?
Intentémoslo. Supón que Dracula toma una foto de la
superficie de Marte y la llama mars.jpg.
Si no tienes una imagen de Marte, puedes crear un archivo binario de prueba de la siguiente manera:
SALIDA
-rw-r--r-- 1 vlad 57095 1.0K Mar 8 20:24 mars.jpgls nos muestra que se creó un archivo de 1-kilobyte.
Está lleno de bytes al azar leídos a partir del archivo especial,
/dev/urandom.
Ahora, supón que Dracula agrega
mars.jpg a su repositorio:
SALIDA
[master 8e4115c] Add picture of Martian surface
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 mars.jpgSupón que Wolfman agregó una imagen similar al mismo tiempo. La suya
es una imagen del cielo de Marte, pero también se llama
mars.jpg. Cuando Dracula intenta hacer
push, recibe un mensaje familiar:
SALIDA
To https://github.com/vlad/planets.git
! [rejected] master -> master (fetch first)
error: failed to push some refs to 'https://github.com/vlad/planets.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.Hemos aprendido que primero debemos hacer pull y resolver conflictos:
Cuando hay un conflicto en una imagen u otro archivo binario, git imprime un mensaje así:
SALIDA
$ git pull origin master
remote: Counting objects: 3, done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
From https://github.com/vlad/planets.git
* branch master -> FETCH_HEAD
6a67967..439dc8c master -> origin/master
warning: Cannot merge binary files: mars.jpg (HEAD vs. 439dc8c08869c342438f6dc4a2b615b05b93c76e)
Auto-merging mars.jpg
CONFLICT (add/add): Merge conflict in mars.jpg
Automatic merge failed; fix conflicts and then commit the result.El mensaje informando el conflicto es básicamente el mismo que se
imprimió para mars.txt, pero hay una línea adicional:
SALIDA
warning: Cannot merge binary files: mars.jpg (HEAD vs. 439dc8c08869c342438f6dc4a2b615b05b93c76e)Git no puede insertar indicadores de conflicto en una imagen como lo hace en los archivos de texto. Por lo tanto, en vez de editar la imagen, debemos revisar la versión que queremos mantener. Luego podemos agregar y hacer commit a esta versión.
En la línea agregada de arriba, Git convenientemente nos dio
identificadores de commit para las dos versiones de
mars.jpg. Nuestra versión es HEAD, y la de
Wolfman es 439dc8c0.... Si queremos usar nuestra versión,
podemos usar git checkout:
BASH
$ git checkout HEAD mars.jpg
$ git add mars.jpg
$ git commit -m "Use image of surface instead of sky"SALIDA
[master 21032c3] Use image of surface instead of skyEn cambio si queremos usar la versión de Wolfman, podemos usar
git checkout con el identificador de
commit de Wolfman, 439dc8c0:
BASH
$ git checkout 439dc8c0 mars.jpg
$ git add mars.jpg
$ git commit -m "Use image of sky instead of surface"SALIDA
[master da21b34] Use image of sky instead of surfaceTambién podemos mantener ambas imágenes. La clave es que no podemos mantenerlas con el mismo nombre. Pero podemos verificar cada versión de forma sucesiva y renombrarla, y luego agregar las versiones renombradas. Primero, revisa cada imagen y renómbrala:
BASH
$ git checkout HEAD mars.jpg
$ git mv mars.jpg mars-surface.jpg
$ git checkout 439dc8c0 mars.jpg
$ mv mars.jpg mars-sky.jpgLuego, elimina la vieja imagen mars.jpg y agrega los dos
archivos nuevos:
BASH
$ git rm mars.jpg
$ git add mars-surface.jpg
$ git add mars-sky.jpg
$ git commit -m "Use two images: surface and sky"SALIDA
[master 94ae08c] Use two images: surface and sky
2 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 mars-sky.jpg
rename mars.jpg => mars-surface.jpg (100%)Ahora ambas imágenes de Marte estan ingresadas en el repositorio, y
mars.jpg ya no existe.
Una típica sesión de trabajo
Te sientas en tu computadora para trabajar en un proyecto compartido que es mantenido en un repositorio Git remoto. Durante tu sesión de trabajo, realizas las siguientes acciones, pero no en éste orden:
-
Hacer cambios agregando el número
100al archivo de textonumbers.txt - Actualizar repositorio remoto para actualizar el repositorio local
- Celebrar tu éxito con cerveza(s)
- Actualizar repositorio local para actualizar el repositorio remoto
- Realizar cambios con los cuales voy a hacer commit
- Hacer commit a los cambios al repositorio local
¿En qué orden deberías hacer estas acciones para minimizar la posibilidad de conflictos? Pon los comandos de arriba en orden en la columna acción de la tabla de abajo. Cuando tengas el orden correcto, ve si puedes escribir los comandos correspondientes en la columna comando. Algunos campos ya están completados para ayudarte a comenzar.
| orden | acción . . . . . . . . . . | comando . . . . . . . . . . |
|---|---|---|
| 1 | ||
| 2 | echo 100 >> numbers.txt |
|
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ¡Celebrar! | AFK |
| orden | acción . . . . . . . . . . | comando . . . . . . . . . . |
|---|---|---|
| 1 | Actualizar repositorio local | git pull origin master |
| 2 | Hacer cambios | echo 100 >> numbers.txt |
| 3 | Realizar cambios | git add numbers.txt |
| 4 | Hacer commit a los cambios | git commit -m "Agregar 100 a numbers.txt" |
| 5 | Actualizar repositorio remoto | git push origin master |
| 6 | ¡Celebrar! | AFK |
- Los conflictos ocurren cuando dos o más personas cambian el mismo archivo(s) al mism/o tiempo.
- El sistema de control de versiones no permite a las personas sobreescribir ciegamente los cambios del otro, pero resalta los conflictos para poder resolverlos.
Content from La ciencia abierta
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 10 minutos
Hoja de ruta
Preguntas
- ¿Cómo un control de versiones me puede ayudar a tener mi trabajo más abierto?
Objetivos
- Explica como el control de versiones nos ayuda a tener un cuaderno electrónico para todo nuestro trabajo computacional.
Lo opuesto a “abierto” no es “cerrado”. Lo opuesto a “abierto” es “quebrado”.
-– John Wilbanks
El libre intercambio de información podría ser el ideal en Ciencia. Pero la realidad, a menudo, es mucho más complicada. En la práctica cotidiana vemos situaciones como la siguiente:
- Una científica recoge algunos datos y los almacena en una máquina que seguramente tiene en su oficina.
- Luego ella escribe y modifica unos pocos programas para analizar los datos (los cuales residen en su computadora).
- Una vez que tiene algunos resultados, ella escribe y presenta su artículo. Podría incluir sus datos -en varias revistas que los requieran- pero probablemente no incluya su código.
- El tiempo pasa.
- La revista envía las revisiones de un puñado de personas anónimas que trabajan en su campo de actividad. Ella revisa su artículo para satisfacer las revisiones propuestas. Durante ese tiempo ella también podría modificar los scripts que escribió anteriormente, y vuelve a enviar.
- Pasa más tiempo.
- El artículo finalmente se publica.
- Se podría incluir un enlace a una copia online de sus datos, pero el mismo artículo está detrás de un sitio web de pago: sólo las personas que tienen acceso personal o institucional serán capaces de leerlo.
Para muchos otros científicos, el proceso abierto se ve así:
- Los datos que obtiene son almacenados, tan pronto como los colecta, en un repositorio de acceso abierto, como puede ser figshare o Zenodo, obteniendo su propio [Digital Object Identifier] (https://en.wikipedia.org/wiki/Digital_object_identifier) (DOI). O los datos que han sido recientemente publicados, son almacenados en Dryad.
- La científica crea un nuevo repositorio en GitHub para guardar su trabajo.
- Al hacer su análisis de los datos, guarda los cambios de sus scripts (y posiblemente algunos archivos de salida) en ese repositorio. También utiliza el repositorio para su artículo. Entonces ese repositorio es el centro de colaboración con sus colegas.
- Cuando está satisfecha con el estado de su artículo, publica una versión en arXiv o en algún otro servidor de preimpresión para invitar a sus compañeros a una retroalimentación.
- Basado en esa retroalimentación, puede escribir varias revisiones antes de enviar finalmente su artículo a la revista.
- El artículo publicado incluye enlaces a su preimpresión y a sus repositorios de código y datos, lo que hace mucho más fácil para otros científicos utilizar este trabajo como punto de partida para su propia investigación.
Este modelo abierto acelera la investigación: el trabajo abierto se cita y se reutiliza. Sin embargo, las personas que quieren trabajar de esta manera necesitan tomar algunas decisiones sobre qué significa exactamente “abierto” y cómo hacerlo. Puedes encontrar más información sobre los diferentes aspectos de la Ciencia Abierta en el libro.
Ésta es una de las muchas razones por las que enseñamos el control de versiones. Cuando se utiliza con diligencia, responde a “cómo” actúa un cuaderno electrónico compartible:
- Las etapas conceptuales del trabajo están documentadas, incluyendo quién hizo qué y cuándo se hizo. Cada paso está marcado con un identificador (el ID de confirmación) de cada uno de los intentos y propósitos.
- Puedes vincular tu documentación de ideas y otros trabajos intelectuales directamente con los cambios que surgen de ellos.
- Puedes referirte a lo que utilizaste en tu investigación para obtener tus resultados computacionales de manera única y recuperable.
- Con un sistema de control de versiones como Git, todo el historial del repositorio es fácil de archivar para siempre.
Haciendo código citable
Esta breve guía de GitHub explica cómo crear un “Digital Object Identifier (DOI)” para tu código, tus artículos, o cualquier cosa alojada en un repositorio de control de versiones.
¿Cuán reproducible es mi trabajo?
Pide a un compañero de laboratorio que reproduzca un resultado que obtuviste utilizando sólo lo que está disponible en un documento publicado o en la web. Luego, trata de hacer lo mismo con los resultados de tu labmate. Finalmente, reproducir los resultados de otro laboratorio.
¿Cómo encontrar un repositorio de datos adecuado?
Navega por Internet durante un par de minutos y echa un vistazo a los repositorios de datos mencionado anteriormente: Figshare, Zenodo, Dryad. Dependiendo de tu campo de investigación, encuentra repositorios reconocidos por la comunidad en tu campo. También puede ser útil estos repositorios de datos recomendados por Nature. Discute con tu vecino qué repositorio de datos deseas abordar para tu proyecto actual y explicale por qué.
¿Puedo publicar código también?
Hay nuevas maneras de publicar código y hacer que sea citable. Uno de ellos se describe en la página principal del mismo GitHub. Básicamente es una combinación de GitHub (donde está el código) y Zenodo (el repositorio que crea el DOI). Lee esta página mientras sabes que ésta es sólo una de las muchas maneras de hacer tu código citable.
- Trabajo científico abierto es más útil y puede ser citado más que si no lo es.
Content from Licencia
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 5 minutos
Hoja de ruta
Preguntas
- ¿Qué información sobre licencias debería incluir en mi trabajo?
Objetivos
- Explicar la importancia de agregar información de licencias a nuestro repositorio de código.
- Escoger la licencia apropiada.
- Explicar las diferencias en licencias y algunas expectativas sociales.
Cuando un repositorio público contiene código fuente, un manuscrito u
otro trabajo creativo, éste debe incluir un archivo con el nombre
LICENCIA o LICENCIA.txt en el directorio base
del repositorio, que indique claramente bajo qué licencia se pone a
disposición el contenido. Esto se debe a que la protección de propiedad
intelectual (y por lo tanto derechos de autor) se aplica automáticamente
a las obras creativas. La reutilización de trabajos creativos sin
licencia es peligrosa, ya que los titulares de los derechos de autor
podrían realizar una demanda por infringir la misma.
Una licencia resuelve el problema otorgando derechos a otros (los licenciatarios) que de otro modo no tendrían. Los derechos que se otorgan y bajo qué condiciones difieren, a menudo de forma leve, de una licencia a otra. En la práctica, algunas licencias son las más populares, y el sitio choosealicense.com te ayudará a encontrar una licencia que se adapte a tus necesidades. Las cosas importantes a considerar son:
- Si deseas abordar los derechos de patente.
- Si necesitas personas que distribuyan los trabajos derivados de tu código fuente.
- Si el contenido al que estás otorgando la licencia es código fuente.
- Si realmente deseas licenciar el código.
Elegir una licencia que sea de uso común hace la vida más fácil para los contribuyentes y los usuarios, porque es probable que ya estén familiarizados con la licencia y no tengan que sortear una jerga específica para decidir si están de acuerdo con la licencia. La Iniciativa Open Source y Free Software Foundation mantienen listas de licencias que pueden son buenas opciones a considerar.
Este artículo sobre licencias de software proporciona una excelente descripción de licencias y de opciones de licencias desde la perspectiva de los científicos que también escriben código.
Al fin de cuentas, lo que importa es que haya información clara sobre cuál es la licencia. Además, es mejor elegir la licencia desde el principio, incluso si se trata de un repositorio que no es público. Retrasar la decisión de sobre qué licencia elegir sólo complica las cosas más adelante, porque cada vez que un nuevo colaborador comienza a contribuir, ellos también tienen derechos de autor y, por lo tanto, se les debe pedir aprobación una vez que se elige una licencia.
¿Puedo usar una Open License?
Investiga si puedes usar una Open license o “Licencia Abierta” en tu software. ¿Puedes hacer eso por tí mismo?, ¿o necesitas permiso de alguien dentro de tu institución? Si necesitas permiso, ¿de quién?
¿Qué licencias ya he aceptado?
Muchas herramientas de software que usamos día a día
(incluyendo las herramientas en este workshop) son
open-source software. Escoge uno de los proyectos de
GitHub de la lista de abajo, o algún otro que te interese. Encuentra la
licencia (usualmente es un archivo que se llama LICENSE o
COPYING) y luego habla con tus compañeros sobre como ésta
licencia te permite o te restringe el uso del software.
¿Es una de las licencias que hemos visto en esta sesión? ¿Qué tan
diferente es ésta licencia?
- Las personas que usan la licencia GPL en su software tienen que asegurarse de que toda la estructura esté bajo ésta licencia; muchas otras licencias no requieren esto.
- La familia de licencias Creative Commons permite a las personas adaptarse a varios requerimientos y restricciones de atribución, la creación de trabajo derivado, compartir el trabajo, y comercialización.
- Personas sin conocimientos de leyes no deberían tratar de escribir nuevas licencias desde cero.
Content from Ejemplo de Referencia o cita
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 2 minutos
Hoja de ruta
Preguntas
- ¿Cómo puedo hacer que mi trabajo sea más fácil de citar?
Objetivos
- Haz que tu trabajo sea más fácil de citar
Te recomendamos que incluyas un archivo llamado CITATION
o CITATION.txt que describa cómo citar o referenciar tu
proyecto. La siguiente cita es de Software
Carpentry:
To reference Software Carpentry in publications, please cite both of the following:
Greg Wilson: "Software Carpentry: Getting Scientists to Write Better
Code by Making Them More Productive". Computing in Science &
Engineering, Nov-Dec 2006.
Greg Wilson: "Software Carpentry: Lessons Learned". arXiv:1307.5448,
July 2013.
@article{wilson-software-carpentry-2006,
author = {Greg Wilson},
title = {Software Carpentry: Getting Scientists to Write Better Code by Making Them More Productive},
journal = {Computing in Science \& Engineering},
month = {November--December},
year = {2006},
}
@online{wilson-software-carpentry-2013,
author = {Greg Wilson},
title = {Software Carpentry: Lessons Learned},
version = {1},
date = {2013-07-20},
eprinttype = {arxiv},
eprint = {1307.5448}
}- Agrega un archivo CITATION al repositorio y explica cómo quieres que tu trabajo sea citado.
Content from Hospedaje
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 10 minutos
Hoja de ruta
Preguntas
- ¿Dónde debería alojar mis repositorios de control de versiones?
Objetivos
- Explicar diferentes opciones para realizar trabajos científicos.
La segunda gran pregunta para los grupos que quieren liberar su trabajo es dónde hospedar su código y datos. Una opción es que el laboratorio, departamento o la universidad provean un servidor, gestionen cuentas y respaldos, etc. El principal beneficio de esto es que clarifica quién es dueño de qué, lo cual es particularmente importante si algún material es sensible (es decir, se relaciona a experimentos que involucran sujetos humanos o pueden ser usados en una patente). Las principales desventajas son el costo de proveer el servicio y su longevidad: un científico que ha pasado diez años colectando datos quisiera asegurarse de que estos estarán disponibles en diez años más, pero eso está más allá del tiempo de vida de muchos de los subsidios que financian la infraestructura académica.
Otra opción es comprar un dominio y pagar a un Proveedor de Servicios de Internet (ISP por sus siglas en inglés) para hospedarlo. Esto da al individuo o grupo mayor control, y le da la vuelta a problemas que pueden surgir cuando se cambien de una institución a otra, pero requiere más tiempo y esfuerzo para configurar que la opción anterior o siguiente.
La tercera opción es utilizar un servicio de hospedaje público como
GitHub, GitLab, BitBucket o SourceForge. Cada uno de estos
servicios provee una interfaz web que permite a las personas crear, ver
y editar sus repositorios de código. Estos servicios también proveen
herramientas de comunicación y gestión de proyectos que incluyen
seguimiento de problemas, páginas wiki, notificaciones de
correo electrónico y revisiones de código. Estos servicios se benefician
de economías de escalamiento y efectos de redes: es más fácil correr un
servicio grande bien que correr varios pequeños servicios al mismo
estándar. También es más fácil para la gente colaborar. Usando un
servicio popular puede ayudar a conectar tu proyecto con una comunidad
que ya está usando el mismo servicio.
Como un ejemplo, Software Carpentry está en GitHub, donde puedes encontrar el código fuente para esta página. Cualquiera con una cuenta de GitHub puede sugerir cambios a este texto.
Usando servicios grandes y bien establecidos puede también ayudarte a
tomar ventaja rápidamente de herramientas poderosas tales como la
Integración Continua (CI por sus siglas en inglés). CI puede
automaticamente construir el ejecutable a partir del codigo fuente y
probar el software automáticamente cada vez que se hace un
commit o se somete un pull request. La
integración directa de CI con un servicio de hospedaje en línea
significa que esta información está presente en cualquier
pull request y ayudar a mantener la integridad y estándares
de calidad del código. Si bien CI está disponible en situaciones de
auto-hospedaje, hay menos configuración y mantenimiento al usar un
servicio en línea. Más aún, estas herramientas son proporcionadas sin
costo alguno para proyectos de código abierto y están también
disponibles para repositorios privados por una cuota.
Barreras Institucionales
Compartir es el ideal de la ciencia, pero muchas instituciones imponen restricciones al compartir, por ejemplo para proteger propiedad intelectual potencialmente patentable. Si encuentras tales restricciones, pudiera ser productivo indagar acerca de las motivaciones ya sea para solicitar una excepción para un proyecto específico o dominio, o para impulsar una reforma institucional más amplia para el apoyo de la ciencia abierta.
¿Mi Trabajo Puede Ser Público?
Averigua si tienes permitido hospedar tu trabajo abiertamente en un repositorio público. ¿Puedes hacer esto unilateralmente, o necesitas permiso de alguien en tu institución? Si ese es el caso, ¿de quién?
- Los proyectos pueden alojarse en servidores de la universidad, en dominios personales o públicas.
- Las reglas con respecto a la propiedad intelectual y el almacenamiento de información confidencial se aplican sin importar dónde se alojan el código y los datos.
Content from Usando Git desde RStudio
Última actualización: 2023-04-27 | Mejora esta página
Tiempo estimado: 10 minutos
Hoja de ruta
Preguntas
- ¿Cómo puedo usar Git desde RStudio?
Objetivos
- Entender cómo usar Git desde RStudio.
Ya que el uso de control de versiones es muy útil cuando escribimos scripts, entonces RStudio esta integrado con Git. Hay algunas otras mas complejas funcionalidades de Git que solamente se pueden usar desde la terminal, pero RStudio tiene una buena interfaz de trabajo para realizar las operaciones más comunes de control de versiones.
RStudio te permite crear un proyecto project asociado a un directorio determinado. Esta es una manera de hacer un seguimiento de los archivos asociados al proyecto. Una manera de tener control de archivos es mediante el uso de un programa de control de versiones. Para empezar a usar RStudio para el control de versiones, comencemos por crear un nuevo proyecto:
Una nueva ventana se abrirá y preguntará cómo queremos crear el proyecto. Tenemos aquí varias opciones. Supongamos que queremos usar RStudio con el repositorio de planetas que ya hemos creado. Como ese repositorio ya está en una carpeta en tu computadora, podemos escoger la opción “Existing Directory”:
¿Puedes ver la opción de “Version Control”?
Aunque no vamos a usar ésta opción aquí, deberías poder ver una opción en el menú que diga “Version Control”. Esta es la opción que debes escoger cuando quieras crear un proyecto en tu computadora mediante una clonación de un repositorio de GitHub. Si esta opción no es visible, probablemente significa que RStudio no sabe donde está tu ejecutable de Git. Revisa esta página para encontrar algunos consejos. Incluso después de instalar Git, si estás usando MacOSX algunas veces puede ser necesario que tengas que aceptar la licencia de XCode
En el siguiente paso, RStudio va a preguntar cuál es la carpeta existente que queremos usar. Haremos click en el navegador de archivos para navegar a la carpeta correcta en tu computadora, y luego haremos click en “Create Project”:
¡Y ya está! Ahora tenemos un proyecto en R que contiene tu propio repositorio. Fíjate que ahora en el menú aparece un botón con “Git” en letras verticales. Esto significa que RStudio ha reconocido que ésta carpeta es un repositorio de Git, así que te proporcionará las herramientas para usar Git:
Para editar los archivos en tu repositorio, puedes hacer click en el archivo desde el panel inferior izquierdo. Ahora vamos a añadir más información sobre Plutón:
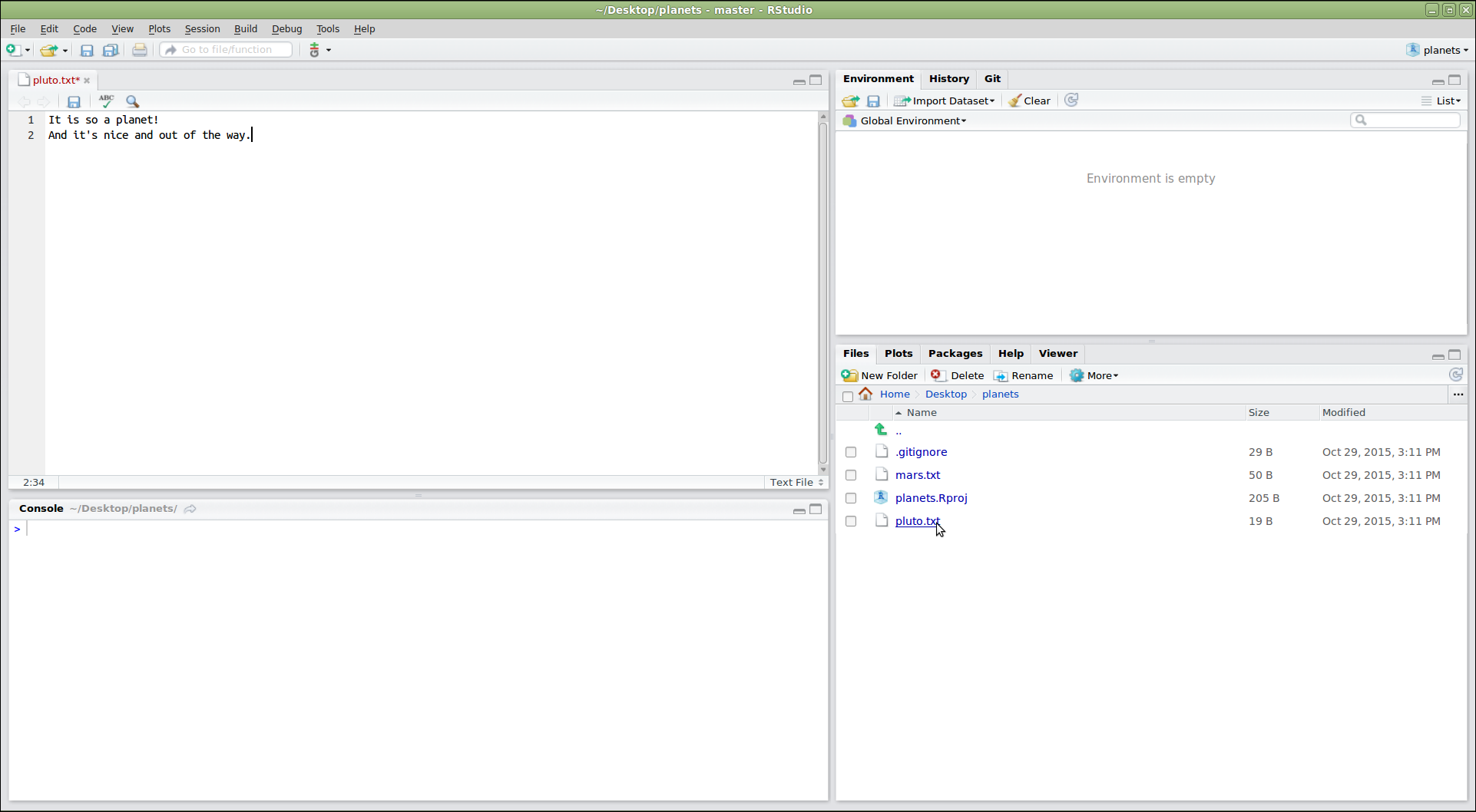
Una vez que hemos guardado nuestros archivos editados, ahora podemos usar RStudio para hacer permanentes los cambios. Usa el botón y haz clik a “Commit”:
Esto abrirá una ventana donde puedes seleccionar qué archivos quieres hacer commit (marca las casillas en la columna “Staged”) y luego escribe un mensaje para el commit (en el panel superior derecho). Los iconos en la columna “Status” indican el estado actual de cada archivo. También puedes ver los cambios de cada archivo haciendo click en su nombre. Una vez que todo esté de la forma que quieres, haz click en “Commit”:
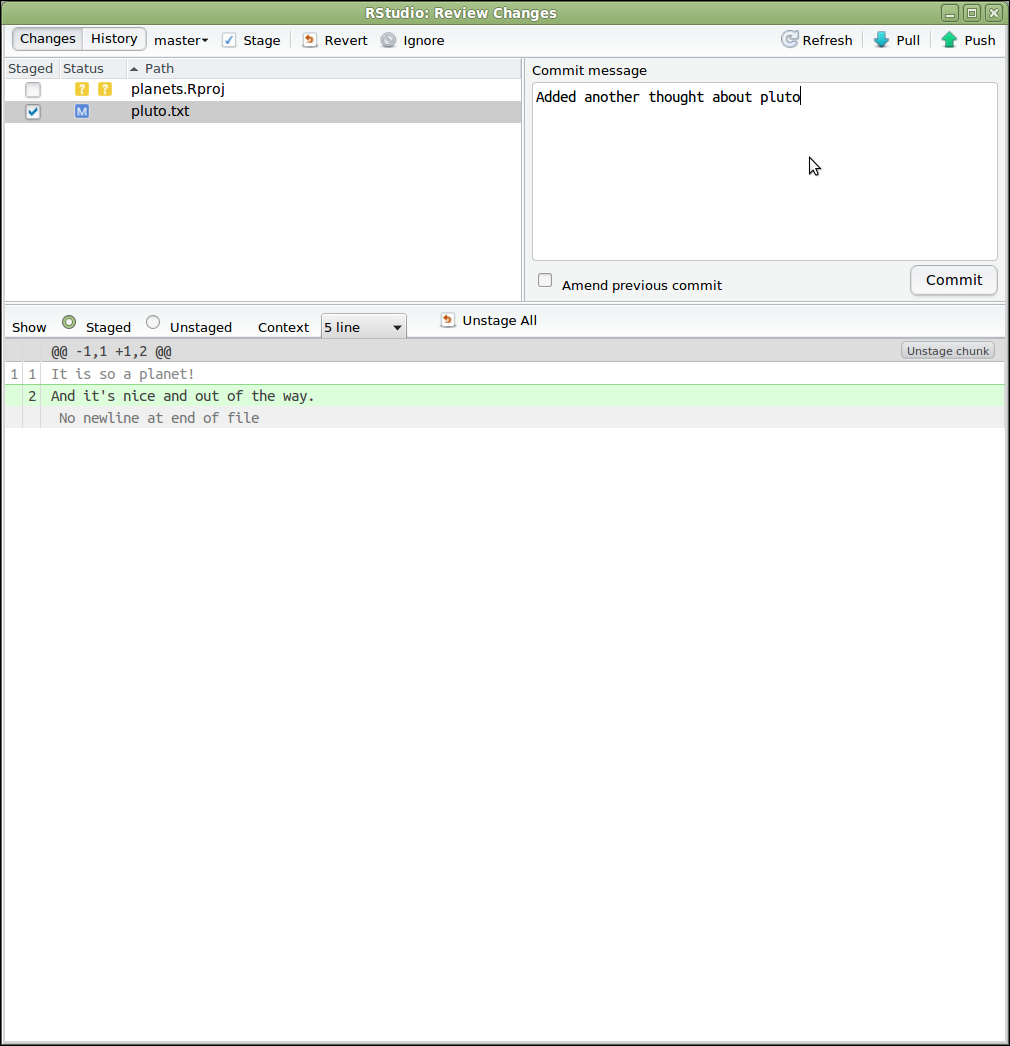
Puedes subir los cambios seleccionando “Push” en el menú de Git. Allí hay también opciones para traer los cambios (hacer pull) desde una versión remota de este repositorio, y ver el historial de cambios realizados:
¿Están los comandos Push y Pull en gris?
Si este es el caso, generalmente significa que RStudio no sabe dónde
están las otras versiones de tu repositorio (por ejemplo, en GitHub).
Para solucionar esto, abre una terminal, sitúate en el repositorio y
luego lanza el siguiente comando:
git push -u origin master. Luego reinicia RStudio.
Si hacemos click en el historial de cambios “History”, podemos ver
una versión gráfica de lo que obtendríamos con el comando
git log:
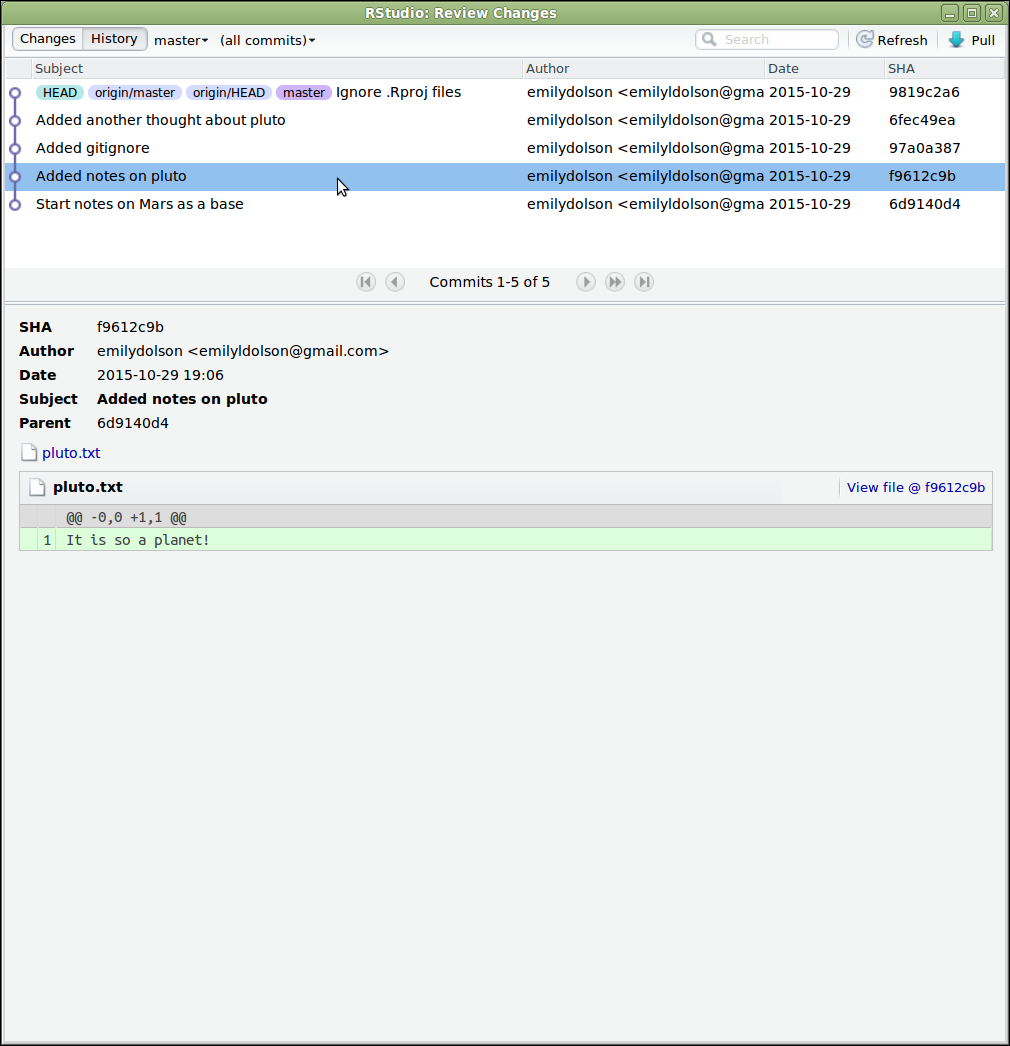
RStudio crea algunos archivos que le ayudan a mantener un control de
los cambios en el proyecto. Normalmente no deseamos que Git los incluya
en el control de versiones, así que es una buena idea agregar sus
nombres al .gitignore:
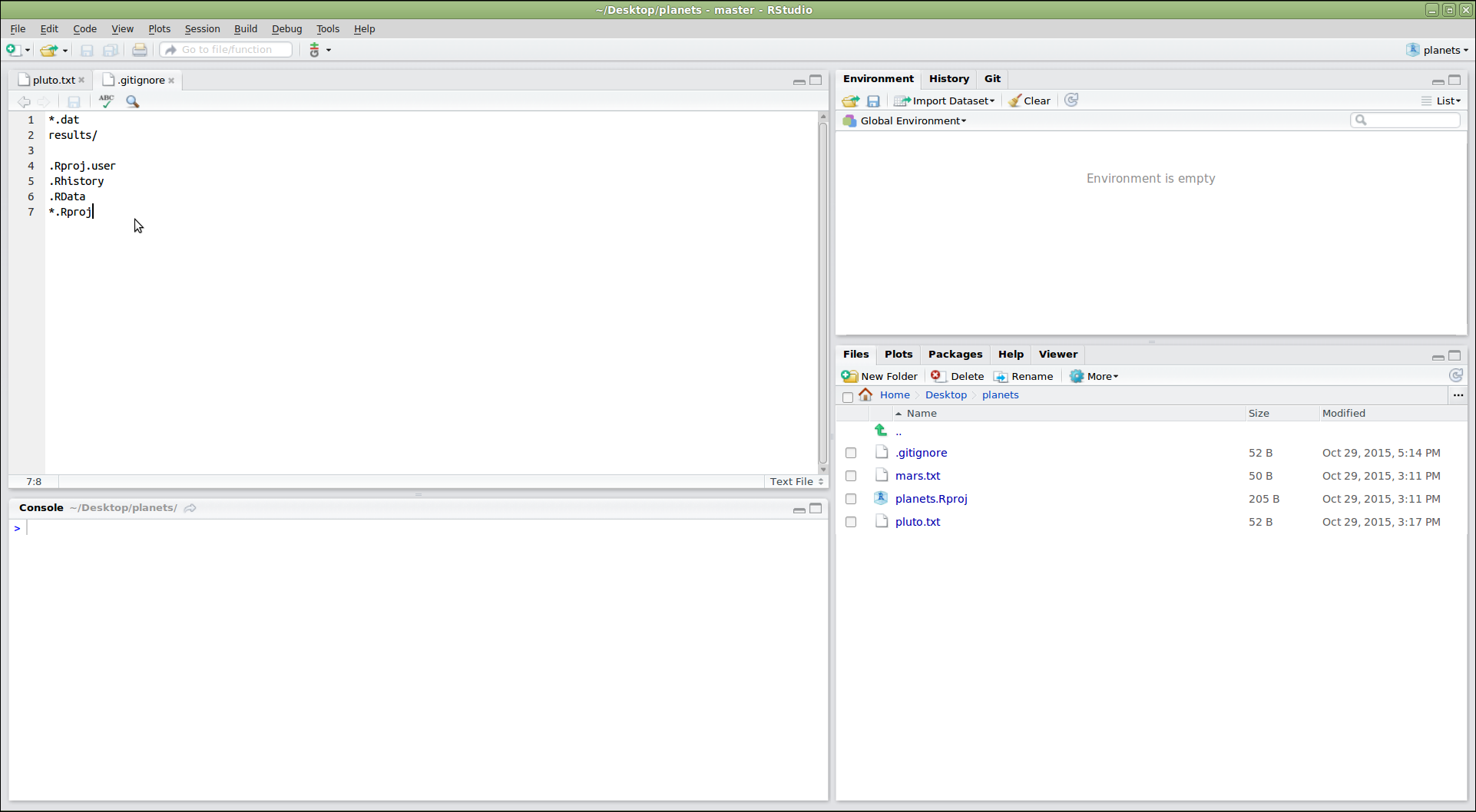
Tip: Control de versiones del output desechable (versioning disposable output)
Generalmente tu no quieres hacer control de cambios o versiones de
tus output desechables (o solo datos de lectura). Entonces, tu debes
modificar el archivo .gitignore para decirle a Git que
ignore estos archivos y directorios.
Challenge
- Crear un directorio dentro de tu proyecto llamado
graphs. - Modificar el archivo
.gitignorepara que contengagraphs/entonces este output desechable no estara versioned.
Agrega el folder recien creado al control de versiones usando la interface de Git.
Esto puede ser realizado con los comandos de linea:
$ mkdir graphs
$ echo "graphs/" >> .gitignore Hay muchas más opciones que se pueden encontrar en la interfaz de RStudio, pero las que hemos visto son suficientes para comenzar.
- Crear un proyecto en RStudio