Managing Research Software Projects
This is an early draft:
please leave feedback in the GitHub repository.
**Roadmap**
* Key features of research software projects
* What "done" looks like
* Basics of project organization, usability
* Social considerations
* Critical fixtures: automated testing, version control
* Making it all happen
**What Kinds of Projects?**
* 3x3: three people for three months
* Contributors are frequently time-slicing other projects
* "Everybody makes coffee"
**Key Features of Research Software Projects**
* Developers have extensive domain knowledge, but are largely self-taught programmers
* Don't know all the right answers, but do know some
* Requirements may be either:
* Discovered as we go along (exploring)
* Relatively stable (engineering)
* Problem is *subtle* as well as *complicated*
* Getting funding, credit can be difficult
**What "Done" Looks Like**
* Software can be used by people other than original authors
* Reproducibility meaningless without this
* Reasonably confident that results are correct
* As good as physical experiment
* Small changes and extensions are easy
* Automated tests make change safe - [Feathers](https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052/)
* Fast enough to be useful
**[Noble's Rules](http://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1000424)**
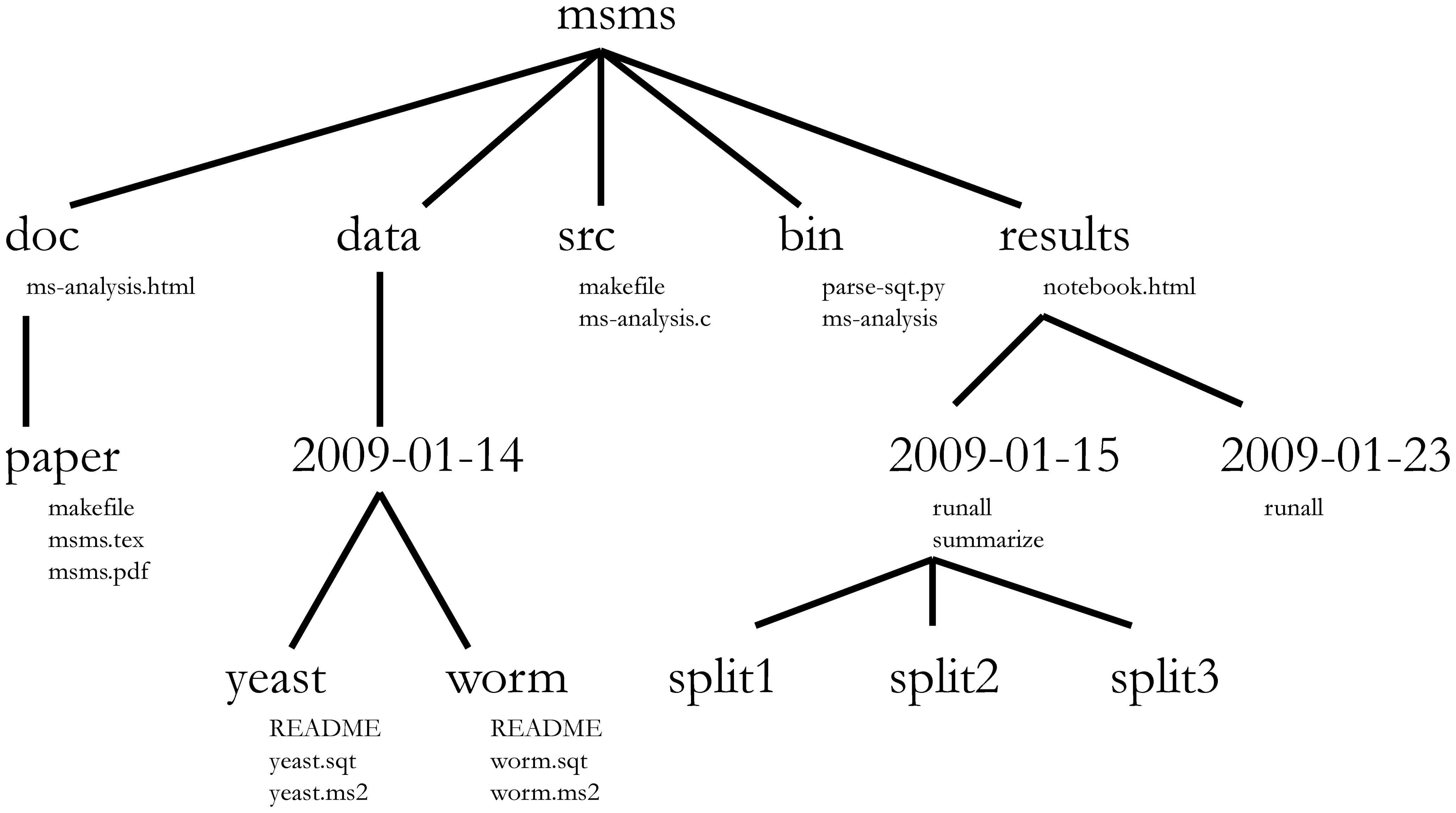
**[Noble's Rules](http://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1000424)**
How to organize small research projects:
* Put each project in its own directory
* Put text documents in `doc/`
* Put raw data and metadata in `data/`
* Put files generated during analysis in `results/`
* Put project source code in `src/`
* Put external scripts, or compiled programs in `bin/`
* Name all files to reflect their content or function
**[Taschuk's Rules](http://oicr-gsi.github.io/robust-paper/)**
How to make research software more robust:
* Have a descriptive README (synopsis, dependencies)
* Provide a descriptive usage statement
* Give the software a meaningful version number
* Make older versions available
* Reuse software (within reason)
**[Taschuk's Rules](http://oicr-gsi.github.io/robust-paper/)** (cont.)
* Do not require root or other special privileges
* Eliminate hard-coded paths
* Enable command-line configuration
* Include a small data set to test installation
* Produce identical results when given identical inputs
From "works on my laptop" to "runs on your cluster".
**Social considerations**
* [Steinmacher](http://www.igor.pro.br/publica/papers/GSD_CSCW2014.pdf)'s analysis of barriers to contribution
* How easy is it to get set up?
* How friendly was reception of first contribution?
* So add the following to Noble's Rules:
* `LICENSE`: terms of re-use
* **Use a standard license** (preferably MIT)
* `CITATION`: how to cite the software
* Get a DOI for the software (see [Zenodo](https://zenodo.org/))
* `CONTRIBUTING`: how to make contributions
* `CONDUCT`: project's social rules
**Social considerations (cont.)**
* Simultaneously selfless and selfish
* makes science easier to evaluate
* makes life easier on your colleagues
* makes it more likely that others will use (and **contribute to!**) your software
* ensures relevancy of your work when funding runs out or maintainer moves on
* more likely to impact traditional academic metrics (i.e. citations)
**Automated Testing**
* Already have correctness tests in place (or should!)
* Invest time to automate these tests
* Execute tests automatically and frequently
* Ensures code changes don't break what already works
**Automated Testing (cont.)**
* How do you know what tests to write?
* Measure code coverage
* Write regression tests for observed bugs
* Test-driven development (more later)
**Kinds of Tests**
* Smoke tests (sanity checks)
* Unit tests (developer-facing)
* Functional tests (user-facing)
* Regression tests (bug-facing)
**Does this look familiar?**
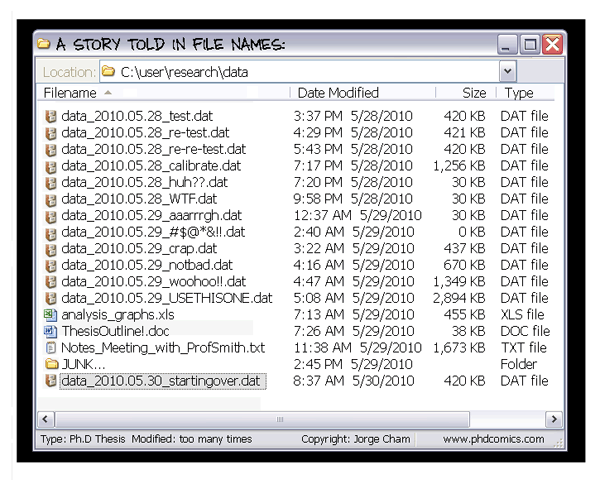
**Discussion**
* What are your best and worst stories of project organization?
* code and/or manuscript
* personal and collaborative
* Consider on your own, then discuss with your neighbor:
* What worked well?
* What didn't work well?
**Version control**
* Provenance (reproducibility)
* Transparency (credibility, trust)
* Collaboration (work in parallel, peer review)
* Hosting (distribution, bug/issue tracking)
* Facilitates worry-free tinkering
* Professional obligation!
See [Ram, 2013](https://dx.doi.org/10.1186%2F1751-0473-8-7) and
[Blischak *et al.*, 2016](https://dx.doi.org/10.1371%2Fjournal.pcbi.1004668)
for an overview.
**From What to How**
* This is the ideal: how do we get there?
* "Traditional" software development is a planning-intensive engineering discipline
* Didn't really have a name until "agile" came along in the 1990s
* Now refer to the engineering approach as "sturdy"
* Differences between the two are much smaller in practice than in theory
**Agile vs. Sturdy**
* Agile: rapid iteration
* informal / underdeveloped / changing requirements
* frequent (daily) short progress updates
* works well for small teams
* Sturdy: "measure twice, cut once"
* formal / mature requirements
* more upfront planning and estimation
* scheduling enforced by manager(s)
* can scale to very large projects
* We're going to focus on common themes
**Code Review**
* Academics review each other's papers; what about code?
* [Petre](http://arxiv.org/abs/1407.5648) found:
* Requires domain knowledge to be useful
* No point doing it at submission time
* But domain experts are scarce
* No incentives to review someone else's thesis project code
* At present, only sustainable within team projects
**Pair Programming**
* Real-time code review
* Knowledge transfer ("we all make coffee")
* Discourages Facebook and Twitter
* At least initially
* Driver and navigator switch roles every hour
* With a short break to stay fresh
* [Empirical studies](https://www.amazon.com/Making-Software-Really-Works-Believe/dp/0596808321/)
confirm effectiveness
**Test-Driven Development (TDD)**
* Approach
* Write the test
* *Then* write the code
* Then clean up and commit
* "Red-green-refactor"
* Writing tests first helps with design
* And ensures tests actually get written
* [Empirical studies](https://www.amazon.com/Making-Software-Really-Works-Believe/dp/0596808321/)
don't confirm effectiveness...
* ...but people who use it swear by it
**Exercise**
* Polygon overlay is one of the basic operations in geographic information systems.
* Simplified version is rectangle overlay.
* Each rectangle is represented as [x0, y0, x1, y1].
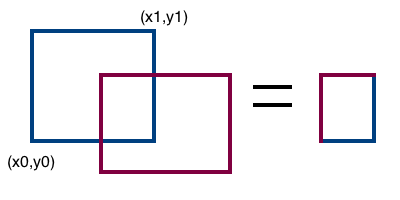
* Given two valid rectangles as input,
`overlay` return the rectangle that is their overlap.
**Exercise**
* What are the three most interesting tests to write for this function?
* Describe in terms of input 1, input 2, expected output, and why it's important.
* Assume input rectangles are well-formed (i.e., nobody's trying to pass in a character string).
* Come up with answers on your own, then compare with your neighbor and select the best three.
**Exercise**
```python
def test_overlay_no_overlap():
rect1 = Rectangle(0, 0, 1, 1)
rect2 = Rectangle(2, 0, 2, 2)
assert overlay(rect1, rect2) == None
def test_overlay_contains():
rect1 = Rectangle(0, 0, 5, 5)
rect2 = Rectangle(2, 2, 3, 3)
assert overlay(rect1, rect2) == Rectangle(0, 0, 5, 5)
def test_shared_edge_or_point():
rect1 = Rectangle(0, 0, 2, 2)
rect2 = Rectangle(2, 1, 3, 3)
assert overlay(rect1, rect2) == Rectangle(2, 1, 2, 2)
rect1 = Rectangle(0, 0, 2, 2)
rect2 = Rectangle(2, 2, 4, 4)
assert overlay(rect1, rect2) == Rectangle(2, 2, 2, 2)
```
**Continuous Integration**
* Tests are already automated, right...RIGHT?!
* Re-run automated tests *before* merging changes
* Ensures baseline is always in runnable state
* CI as a service
* free for open-source projects
* pay for private projects
* Run CI internally
* free open-source solutions
* bring your own hardware (& configuration)
**Ticketing Systems**
* A common fixture on code hosting services
* Use them to track:
* What's broken
* What needs to be added
* Who's working on what
* Great place to foster open discussion
**Compromises**
* "Technical debt"
* dissonance between conceptual model and model reflected in code
* informed, deliberate suspension of best practice
* Necessary to get project off the ground
* Complicates sustained development
* debt must be paid down
**Compromises (cont.)**
* Iterative development
* Build a quick prototype
* Test accuracy
* If performance is unsatisfactory:
* profile performance empirically
* optimize code surgically
* Clean up code
**Compromises (cont.)**
* Incremental improvement ([Petre](http://arxiv.org/abs/1407.5648))
* Don't to fix everything at once
* Instead, whenever you touch a function to fix or extend it, clean it up then.
* Check for code clarity
* Improve documentation / comments
* Write a unit test
* Improvements will accumulate quickly
**Compromises (cont.)**
* Compromise on best practices if you must!
* but not on version control
* and not on automated testing
**[Stupidity-Driven Development](http://ivory.idyll.org/blog/2014-research-coding.html)**
* Write **lots** of tests for scientific core of the code
* Start with many fewer tests for other project components
* When bugs are encountered:
* write new regression tests specific to that bug
* fix the observed bug
* get on with more important things
**[Stupidity-Driven Development](http://ivory.idyll.org/blog/2014-research-coding.html)**
Avoids wasting time writing tests for bugs that never appear!
**Finally, A Note on Overtime**
* [Robinson](http://www.igda.org/?page=crunchsixlessons):
working overtime when you're late only makes you later
* Every all nighter reduces cognitive function 25%
* So after two all nighters,
you would not legally be considered competent to care for yourself
* Optimal work cycle is:
* 45-50 minutes of work + 10 minutes of activity
* 8 hours/day
* 5 days/week
