Given data of the following form:
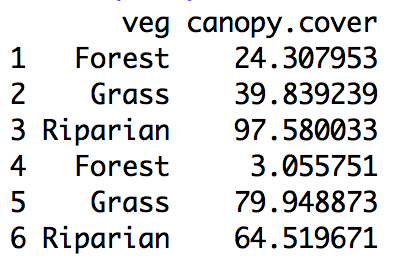
with veg as a factor and canopy.cover numeric, and the following function definition
aggregate(x, by, FUN, …, simplify = TRUE)
| x | an R object. |
| by | a list of grouping elements, each as long as the variables in x. |
| FUN | a function to compute the summary statistics which can be applied to all data subsets. |
| simplify | a logical indicating whether results should be simplified to a vector or matrix if possible. |
which of the following function calls will execute correctly?
a. aggregate(data[“canopy.cover”], by=data[“veg”], FUN=mean)
b. aggregate(data$canopy.cover, by=data$veg, FUN=mean)
c. aggregate(data, by=data$veg, FUN=mean)
d. aggregate(data[,2], by=data[,1], FUN=mean)
- Write a function to calculate the mean and standard error across for canopy cover across the three vegetation types, and make sure it can handle NA values.