We still want to know the number of lines in the files. wc takes options -l to show just the number of lines, but the list is clearly too long to scan for the smallest number. How can we make the computer do this?
Our first step toward a solution is to run the command:
$ wc -l *.pdb > lengthsThe > tells the shell to redirect the command's output to a file instead of printing it to the screen. The shell will create the file if it doesn't exist, or overwrite it if it does.
This is why there is no screen output: the wc output has gone into the file lengths instead.
$ ls lengths
lengths
head lengthsGreat! Now that the lengths are in a file, we can sort them:
$ sort lengthsOh. the output went to the screen, and the lengths file isn't changed. Let's capture the output in another file:
$ sort lengths > sorted-lengthsThen we can use head -1 to get the shortest file:
$ head -1 sorted-lengthsFortunately, the shell gives us a tool for combining these commands. It's |, and it's called a pipe. It allows the shell to redirect the output of a command to the input of the next one, effectively creating a pipeline that our data can flow through, with different processing at each stage. We can use it to combine the three commands wc, sort, and head in one line:
$ wc -l *.pdb | sort | head -1How pipes work
Every time we run a command, the computer creates a process in memory to do the work. Every process has an input channel called standard input, stdin, and also an output channel called standard output stdout. Normally, the the input channel for the shell is the keyboard, and the output channel is the screen. The >, >>, < and | characters on the command line tell the shell to get the input (<,|) or send the (>, >>, |) someplace else.

When we run wc -l *.pdb > lengths, the computer to creates a new process. Then wc reads from the input files (given in the command). We've also used >, so instead of sending the output to the default stdout (the screen), it sends it to the file we specify.
When we run a pipe, like wc -l *.pdb | sort, the shell creates two processes (one for each process in the pipe) so that wc and sort run simultaneously. The standard output of the first process (wc) is fed directly to the standard input of the next (sort). This can continue down a series of pipes. With the command wc -l *.pdb | sort | head -1, we get three processes with data flowing from the files, through wc to sort, and from sort through head to the screen.
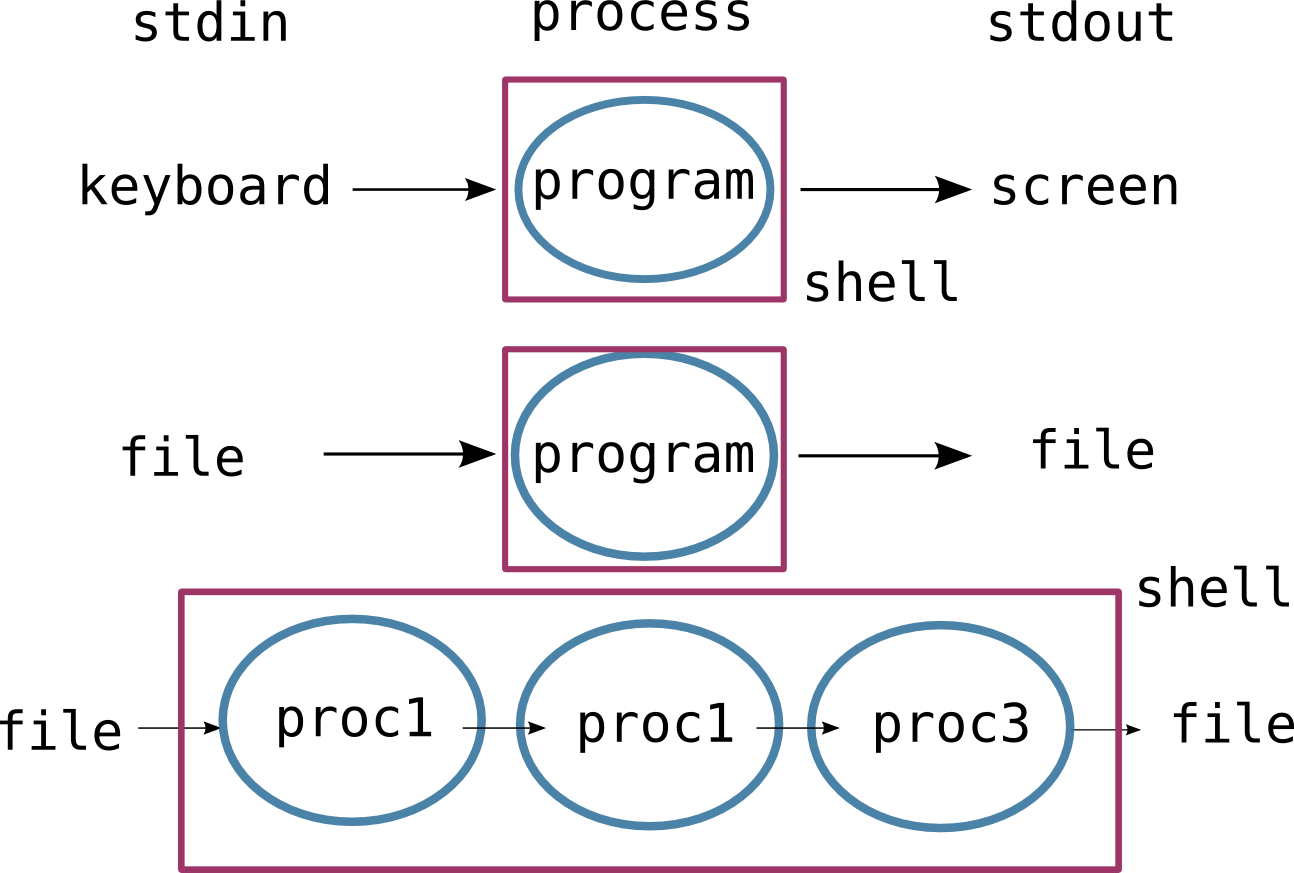
Almost all of the standard Unix tools can work this way: unless told to do otherwise, they read from standard input, do something with what they've read, and write to standard output.
This simple idea is why Unix has been so successful. The key is that any program that reads lines of text from standard input and writes lines of text to standard output can be combined with every other program that behaves this way. You can and should write your programs this way so that you and other people can put those programs into pipes to multiply their power.